Web Technologies
- Distributed Computing / Big Data 2020
Join Linked in Group - Big Data
The Limits of Traditional Data Warehouse Technogy;
- Fault-tolerance a scale - could not scale
- Can't handle variety of data types such as video.
- Need to be archived to manage huge volume of data
- Parallelism was an add-on
- Not suited for compute-intensive deep analytics
- Price-performance is not better than emerging big data technology
The big three of Big Data:
- Map-reduce
- Distributed file system
- Data Base
Here is an interesting article addressing the issues that Big Data to resolve for its success:
Why Big Data Fails?- Lack of accessing API to the data from the domain experts who can analyze the data. We need hybrid models which combine the power of MapReduce with the ease-of-use of SQL are required. In other words, we need data discovery platform. "Hadoop is a great technology for storing large volumes of data at a low cost... but the problem is that the only people who can get the data out are the people who put the data in."
- A Three-Platform Approach: Data Archive, Discovery, Production Analytics.
My tutorial for Hadoop:
Here is how Facebook made improvements to the open source Apache Giraph graph-processing platform. The project, which is built on top of Hadoop:
- Facebook has detailed its extensive improvements to the open source Apache Giraph graph-processing platform. The project, which is built on top of Hadoop, can now process trillions of connections between people, places and things in minutes."
Facebook's trillion-edge, Hadoop-based and open source graph-processing engine - from GigaOM, Aug, 2013
Distribute Computing is a field of computer science studying distributed system. A distributed system consists of multiple nodes that communicate via network. The computers in each node interact each other to accomplish a shared goal.
Google Code University - Introduction to Distributed System Design
In other words, distributed computing uses distributed systems to solve problems.
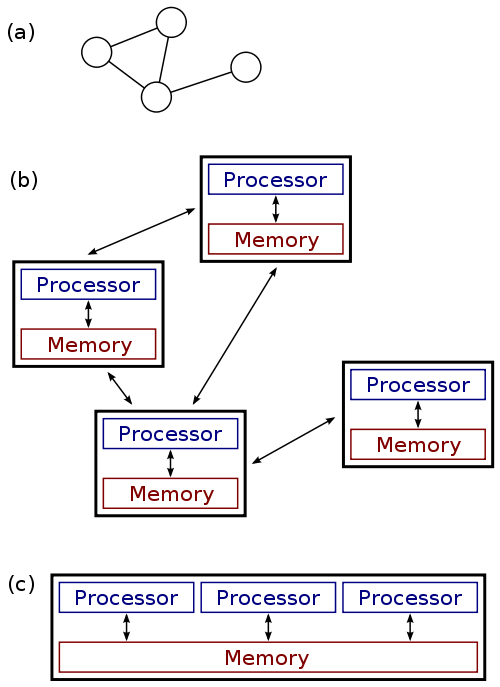
image source wiki
Three-tier architecture is a client-server architecture. The presentation, the application processing, and the data management are logically separate processes.
For example, an application that uses middleware to service data requests between a user and a database employs multi-tier architecture. The most widespread use of multi-tier architecture is the three-tier architecture.
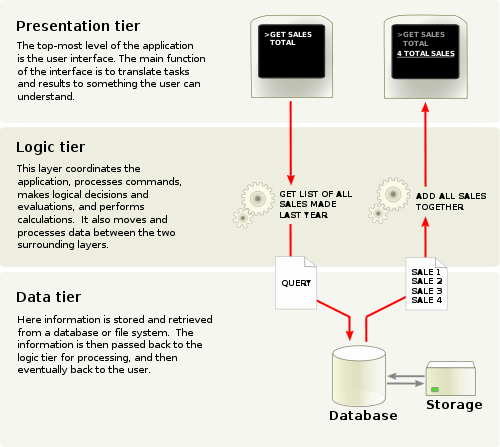
image source wiki
Apache Hadoop, for more information.
Hadoop is a framework for running applications on large cluster built of commodity hardware. It has two main components:
- Map/Reduce
It is a computational paradigm, where the application is divided into many small fragments of work, each of which may be executed or re-executed on any node in the cluster. - Hadoop distributed file system (HDFS)
It stores data on the compute nodes, providing very high aggregate bandwidth across the cluster.
Both Map/Reduce and the Hadoop Distributed File System are designed so that node failures are automatically handled by the framework.
There are other components of Hadoop:
- HBase:
HBase is the Hadoop database. Think of it as a distributed, scalable, big data store. - Cassandra:
Apache Cassandra is an open source distributed database management system. It is a NoSQL solution that was initially developed by Facebook and powered their Inbox Search feature until late 2010. - Hive:
Hive is a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop compatible file systems. So, actually, it converts SQL-like language to Map-Reduce programs.
Netflix is at it again, this time showing off its homemade architecture for running Hadoop workloads in the Amazon Web Services cloud. It's all about the flexibility of being able to run, manage and access multiple clusters while eliminating as many barriers as possible.
Netflix shows off its Hadoop architecture, Jan 10, 2013
Also, worth to know a technology called memcached.
Google research publication:
- pdf - MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat
- html - http://research.google.com/archive/mapreduce-osdi04-slides/index.html
MapReduce is a framework for processing huge datasets on certain kinds of distributable problems using a large number of nodes, collectively referred to as a cluster. Computational processing can occur on data stored either in a filesystem (unstructured) or within a database.
MapReduce is using the combination of the two competing technologies from the parallel computing paradigms (see the table below). In other words, MapReduce is using message-passing, data-parallelism, pipelined (map phase and reduce phase) work with high level of abstraction (programmer does not have to worry about the implementation of parallel processing (such as which processor to use, how many processors should be used, or parallel algorithm to use). All programmer needs to do is to specify the tasks for mapper/reducer.
| Shared Memory | Message Passing |
|---|---|
| partitioning work | partitioning data |
| share data lock(Data[i]) work(Wp) unlock(Data[i]) |
work on slice of data Data[p...p+(n/p)-1] information exchange between partitioned data |
MapReduce has two steps:
- Map step:
The master node takes the input, chops it up into smaller sub-problems, and distributes those to worker nodes. A worker node may do this again in turn, leading to a multi-level tree structure. The worker node processes that smaller problem, and passes the answer back to its master node. - Reduce step:
The master node then takes the answers to all the sub-problems and combines them in a way to get the output - the answer to the problem it was originally trying to solve. The map-deduce platform is responsible for routing pairs to reducers. In other words, the same key should be directed to the same reducer.
| Mappers | Reducers |
|---|---|
| take in k1, v1 pairs emit k2, v2 pairs |
receive all pairs for k2 combine these |
| map(k1,v1)->k2,v2 | reduce(k2,[...v2...]->k2,f(...v2...) |
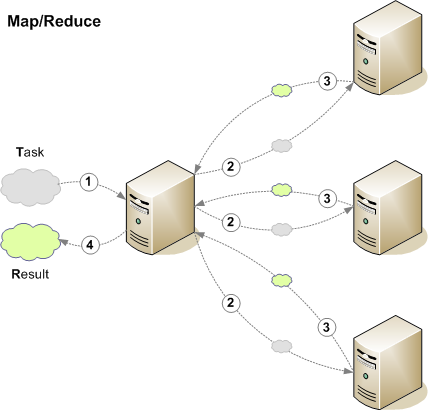
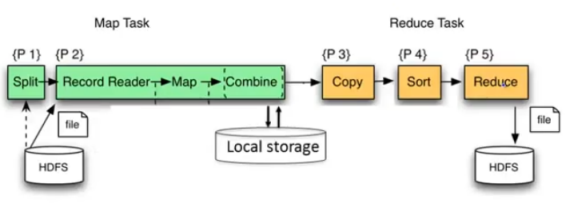
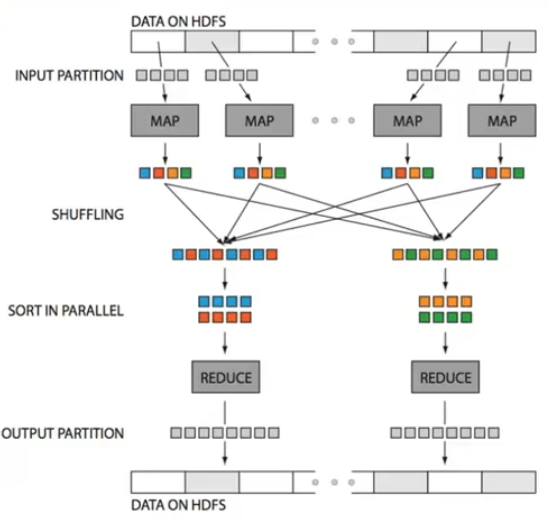
Source: Huy Vo, NYU Poly
- What can MapReduce learn from Database?
- Declarative languages are a good thing.
- Schemas are important.
- What can Database learn from MapReducde?
- Query fault-tolerance.
- Support for in situ data.
- Embrace open-source.
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization