Artificial Neural Network (ANN) 2 - Forward Propagation
Continued from Artificial Neural Network (ANN) 1 - Introduction.
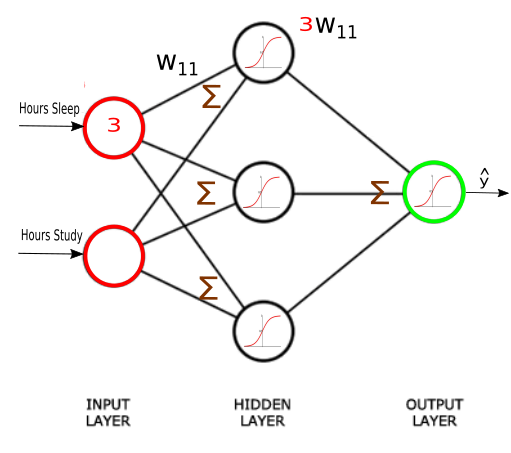
Our network has 2 inputs, 3 hidden units, and 1 output.
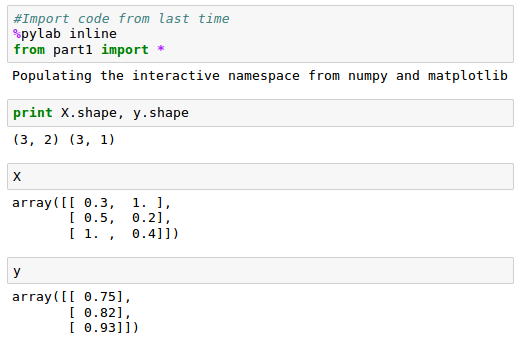
This time we'll build our network as a python class.
The init() method of the class will take care of instantiating constants and variables.

$$ \begin{align}z^{(2)} = XW^{(1)} \tag 1\\ a^{(2)} = f \left( z^{(2)} \right)& \tag 2\\ z^{(3)} = a^{(2)} W^{(2)} \tag 3\\ \hat y = f \left( z^{(3)} \right) \tag 4 \end{align} $$
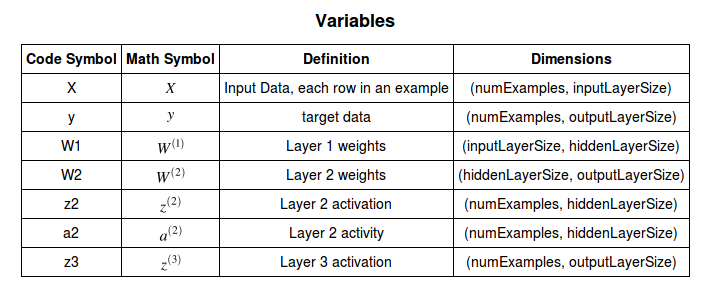
Each input value in matrix $X$ should be multiplied by a corresponding weight and then added together with all the other results for each neuron.
$z^{(2)}$ is the activity of our second layer and it can be calculated as the following:
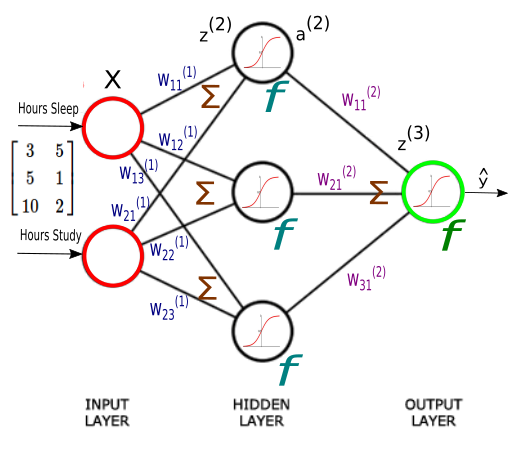
$$ z^{(2)} = XW^{(1)} \tag 1 $$ $$ = \begin{bmatrix} 3 & 5 \\ 5 & 1 \\ 10 & 2 \end{bmatrix} \begin{bmatrix} W_{11}^{(1)} & W_{12}^{(1)} & W_{13}^{(1)}\\ W_{21}^{(1)} & W_{22}^{(1)} & W_{23}^{(1)} \end{bmatrix} $$ $$ = \begin{bmatrix} 3 W_{11}^{(1)} + 5 W_{21}^{(1)} & 3 W_{12}^{(1)} + 5 W_{22}^{(1)} & 3 W_{13}^{(1)} + 5 W_{23}^{(1)} \\ 5 W_{11}^{(1)} + W_{21}^{(1)} & 5 W_{12}^{(1)} + W_{22}^{(1)} & 5 W_{13}^{(1)} + W_{23}^{(1)} \\ 10 W_{11}^{(1)} + 2 W_{21}^{(1)} & 10 W_{12}^{(1)} + 2 W_{22}^{(1)} & 10 W_{13}^{(1)} + 2 W_{23}^{(1)} \end{bmatrix} $$Note that each entry in $z$ is a sum of weighted inputs to each hidden neuron. $z$ is $3 \times 3$ matrix, one row for each sample, and one column for each hidden unit.
Now that we have the activities for our second layer, $ z^{(2)} = XW^{(1)} $, we need to apply the activation function.
We'll independently apply the sigmoid function to each entry in matrix $z$:
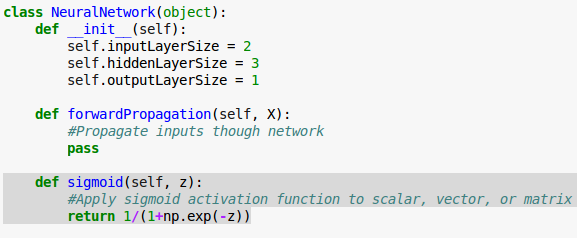
By using numpy we'll apply the activation function element-wise, and return a result of the same dimension as it was given:
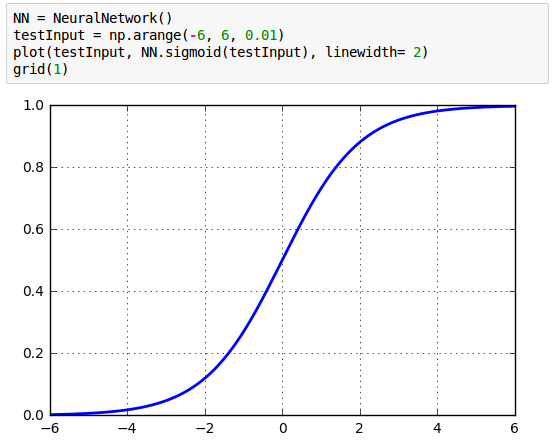
Let's see how the sigmoid() takes an input and how returns the result:
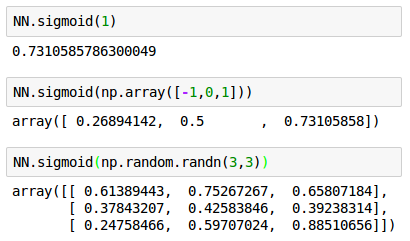
The following calls for the sigmoid() with args : a number (scalar), 1-D (vector), and 2-D arrays (matrix).
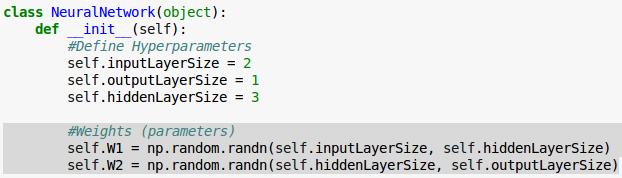
We initialize our weight matrices ($W^{(1)}$ and $W^{(2)}$) in our __init__() method with random numbers.
We now have our second formula for forward propagation, using our activation function($f$), we can write that our second layer activity: $a^{(2)} = f \left( z^{(2)} \right)$. The $a^{(2)}$ will be a matrix of the same size ($3 \times 3$):
$$ a^{(2)} = f(z^{(2)}) \tag 2 $$To finish forward propagation we want to propagate $a^{(2)}$ all the way to the output, $\hat y$.
All we have to do now is multiply $a^{(2)}$ by our second layer weights $W^{(2)}$ and apply one more activation function. The $W^{(2)}$ will be of size $3 \times 1$, one weight for each synapse:
$$ z^{(3)} = a^{(2)} W^{(2)} \tag 3 $$Multiplying $a^{(2)}$, a ($3 \times 3$ matrix), by $W^{(2)}$, a ($3 \times 1$ matrix) results in a $3 \times 1$ matrix $z^{(3)}$, the activity of our 3rd layer. The $z^{(3)}$ has three activity values, one for each sample.
Then, we'll apply our activation function to $z^{(3)}$ yielding our estimate of test score, $\hat y$:
$$ \hat y = f \left( z^{(3)} \right) \tag 4 $$Now we are ready to implement forward propagation in our forwardPropagation() method, using numpy's built in dot method for matrix multiplication:
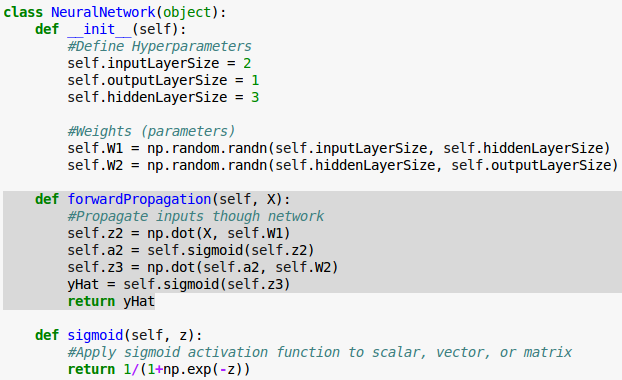
Now we have a class capable of estimating our test score given how many hours we sleep and how many hours we study. We pass in our input data ($X$) and get real outputs ($\hat y$).
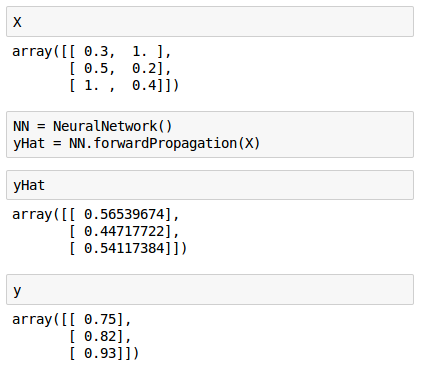
Note that our estimates ($\hat y$) looks quite terrible when compared with our target ($y$). That's because we have not yet trained our network, that's what we'll work on next article.
Next:
Machine Learning with scikit-learn
scikit-learn installation
scikit-learn : Features and feature extraction - iris dataset
scikit-learn : Machine Learning Quick Preview
scikit-learn : Data Preprocessing I - Missing / Categorical data
scikit-learn : Data Preprocessing II - Partitioning a dataset / Feature scaling / Feature Selection / Regularization
scikit-learn : Data Preprocessing III - Dimensionality reduction vis Sequential feature selection / Assessing feature importance via random forests
Data Compression via Dimensionality Reduction I - Principal component analysis (PCA)
scikit-learn : Data Compression via Dimensionality Reduction II - Linear Discriminant Analysis (LDA)
scikit-learn : Data Compression via Dimensionality Reduction III - Nonlinear mappings via kernel principal component (KPCA) analysis
scikit-learn : Logistic Regression, Overfitting & regularization
scikit-learn : Supervised Learning & Unsupervised Learning - e.g. Unsupervised PCA dimensionality reduction with iris dataset
scikit-learn : Unsupervised_Learning - KMeans clustering with iris dataset
scikit-learn : Linearly Separable Data - Linear Model & (Gaussian) radial basis function kernel (RBF kernel)
scikit-learn : Decision Tree Learning I - Entropy, Gini, and Information Gain
scikit-learn : Decision Tree Learning II - Constructing the Decision Tree
scikit-learn : Random Decision Forests Classification
scikit-learn : Support Vector Machines (SVM)
scikit-learn : Support Vector Machines (SVM) II
Flask with Embedded Machine Learning I : Serializing with pickle and DB setup
Flask with Embedded Machine Learning II : Basic Flask App
Flask with Embedded Machine Learning III : Embedding Classifier
Flask with Embedded Machine Learning IV : Deploy
Flask with Embedded Machine Learning V : Updating the classifier
scikit-learn : Sample of a spam comment filter using SVM - classifying a good one or a bad one
Machine learning algorithms and concepts
Batch gradient descent algorithmSingle Layer Neural Network - Perceptron model on the Iris dataset using Heaviside step activation function
Batch gradient descent versus stochastic gradient descent
Single Layer Neural Network - Adaptive Linear Neuron using linear (identity) activation function with batch gradient descent method
Single Layer Neural Network : Adaptive Linear Neuron using linear (identity) activation function with stochastic gradient descent (SGD)
Logistic Regression
VC (Vapnik-Chervonenkis) Dimension and Shatter
Bias-variance tradeoff
Maximum Likelihood Estimation (MLE)
Neural Networks with backpropagation for XOR using one hidden layer
minHash
tf-idf weight
Natural Language Processing (NLP): Sentiment Analysis I (IMDb & bag-of-words)
Natural Language Processing (NLP): Sentiment Analysis II (tokenization, stemming, and stop words)
Natural Language Processing (NLP): Sentiment Analysis III (training & cross validation)
Natural Language Processing (NLP): Sentiment Analysis IV (out-of-core)
Locality-Sensitive Hashing (LSH) using Cosine Distance (Cosine Similarity)
Artificial Neural Networks (ANN)
[Note] Sources are available at Github - Jupyter notebook files1. Introduction
2. Forward Propagation
3. Gradient Descent
4. Backpropagation of Errors
5. Checking gradient
6. Training via BFGS
7. Overfitting & Regularization
8. Deep Learning I : Image Recognition (Image uploading)
9. Deep Learning II : Image Recognition (Image classification)
10 - Deep Learning III : Deep Learning III : Theano, TensorFlow, and Keras
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization