Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis II
In my previous article (Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis I), we learned about the bag-of-words model and tf-idfs.
In this article, we are going to see how we split the text corpora into individual elements. In other words, we need to tokenize documents into individual words by splitting the cleaned document at its whitespace characters.
Then, we will train a logistic regression model to classify the movie reviews into positive and negative reviews.
Also, we need to learn how to handle real world's big datasets.
Natural Language Processing (NLP): Sentiment Analysis I (IMDb & bag-of-words)
Natural Language Processing (NLP): Sentiment Analysis II (tokenization, stemming, and stop words)
Natural Language Processing (NLP): Sentiment Analysis III (training & cross validation)
Natural Language Processing (NLP): Sentiment Analysis IV (out-of-core)
Here is our dataset we introduced in the previous article:
Before we build our bag-of-words model, we may want to clean up our movie review dataset by stripping it of all unwanted characters.
As the first step, we want to test with the last 300 characters from the first document in the reshuffled movie review dataset:
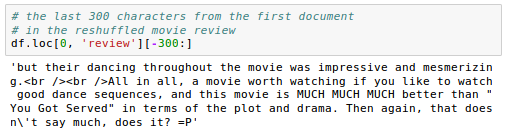
As we can see from the output, the text contains punctuation as well as HTML and other characters.
While HTML markup does not contain much useful semantics, punctuation marks can represent useful NLP contexts. However, just for now, we may want to remove all punctuation marks while keeping emoticon characters such as ":)" since those are certainly useful for sentiment analysis.
To accomplish the task, we're going to use regular expression (regex) library, re, as shown below:

Using the first regex <[^>]*>, we can remove the entire HTML markup. Then, we use a little bit more complex regex to find emoticons, which we temporarily stored as emoticons. Next, we remove all non-word characters from the text using the regex [\W]+, and converted the text into lowercase characters. Then, we're eventually adding the temporarily stored emoticons to the end of the processed document string. Finally, we remove the nose character(-) from the emoticons for consistency.
Let's check if our clean-up works correctly:
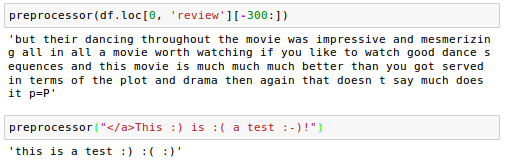
Now we need to apply the preprocessor to all of our movie reviews in our DataFrame:
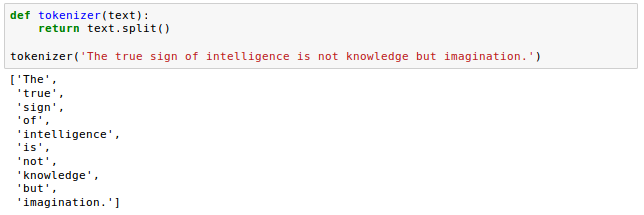
Tokenization is the process of breaking up a stream of text into words, phrases, or other meaningful elements called tokens.
The tokens are then used as an input for parsing or text mining.
Usual way of tokenizing documents is to split them into individual words using whitespace delimiter:
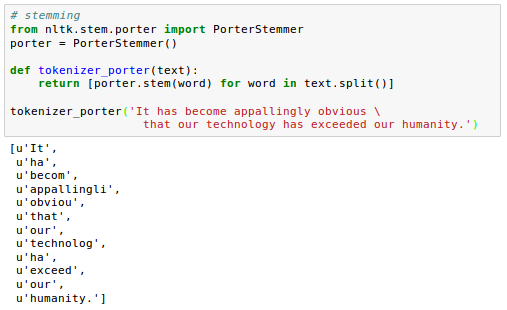
Stemming transforms a word into its root form that allows us to map related words to the same stem.
We'll use Porter stemming algorithm from Natural Language Toolkit for Python (NLTK, http://www.nltk.org ):
The Porter stemming algorithm is probably the oldest and simplest stemming algorithm.
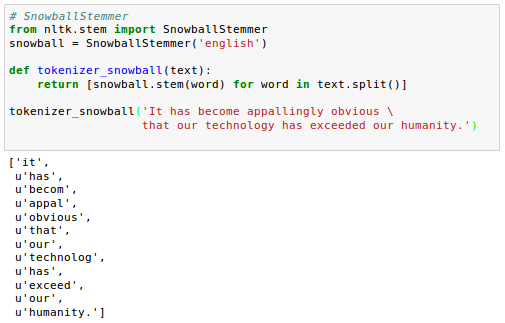
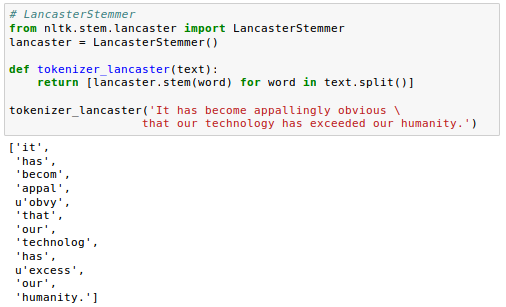
Other popular stemming algorithms include the newer Snowball stemmer (Porter2 or "English" stemmer) or the Lancaster stemmer (Paice-Husk stemmer), which is faster but also more aggressive than the Porter stemmer.
Those alternative stemming algorithms are also available through the NLTK package (http://www.nltk.org/api/ nltk.stem.html).
Snowball stemmer example:
Lancaster stemmer example:
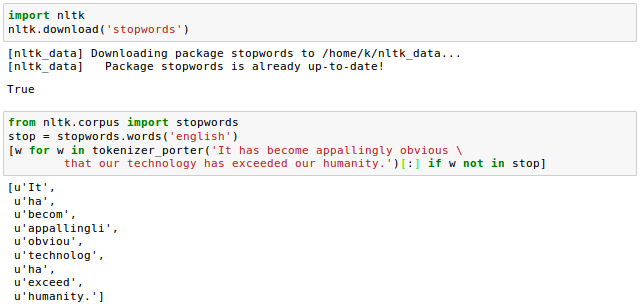
Stop words usually refer to the most common words in a language, there is no single universal list of stop words used by all natural language processing tools, and indeed not all tools even use such a list. Some tools specifically avoid removing these stop words to support phrase search - wiki
Stop-words are those words that are extremely common in all sorts of texts and likely bear little useful information that can be used to distinguish between different documents.
Examples of stop-words are is, and, has, and so on.
NLTK library provides the set of 127 English stop-words, and we're going to use it to remove stop-words from the movie reviews:
Github Jupyter notebook is available from Sentiment Analysis
Next: Machine Learning (Natural Language Processing - NLP): Sentiment Analysis III
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization