Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis IV
In previous series of articles starting from (Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis I), we worked with imdb data and got machine learning model which can predict whether a movie review is positive or negative with 90 percent accuracy.
However, it took a while to get the results since it was computationally quite expensive to construct the feature vectors for the 50,000 movie review dataset during grid search.
So, in this article, we are going to apply a technique called out-of-core learning (external memory algorithms) that allows us to work with such large datasets.
The out-of-core learning algorithms are designed to process data that is too large to fit into a computer's main memory at one time. Such algorithms must be optimized to efficiently fetch and access data stored in slow bulk memory such as hard drives.
Natural Language Processing (NLP): Sentiment Analysis I (IMDb & bag-of-words)
Natural Language Processing (NLP): Sentiment Analysis II (tokenization, stemming, and stop words)
Natural Language Processing (NLP): Sentiment Analysis III (training & cross validation)
Natural Language Processing (NLP): Sentiment Analysis IV (out-of-core)
In this section, we will make use of the partial_fit function of the scikit-learn's SGDClassifier to stream the documents directly from our local drive and train a logistic regression model using small minibatches of documents.
Let's define a tokenizer function that cleans the unprocessed text data from our movie_data.csv file that we constructed in Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis I.
We also define a generator function, stream_docs(), that reads in and returns one document at a time via yield():
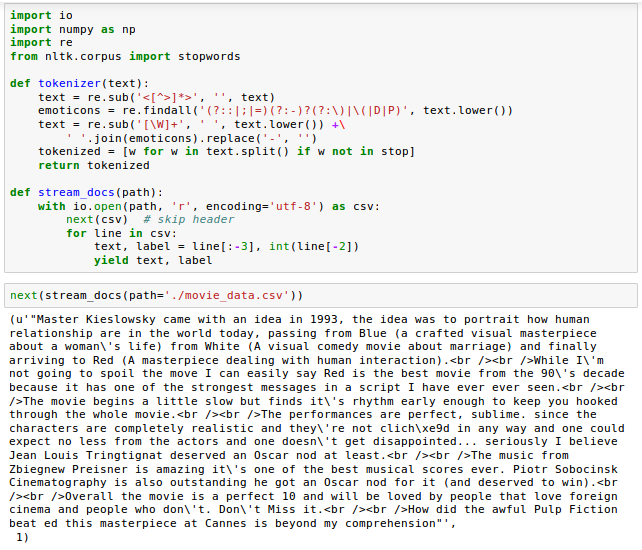
To check if our stream_docs() function works correctly, we read in the first document from the movie_data.csv file. It returned a tuple consisting of the review text as well as the corresponding class label which is at the end of output ('1').
As we can see from the output below we can see the stream_docs() is working fine:
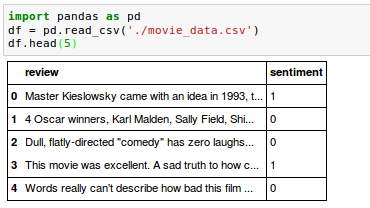
We will now define a function, get_minibatch(), that will take a document stream from the stream_docs() function and return a particular number of documents specified by the size parameter:

In our previous article, we used CountVectorizer to convert text documents to a matrix of token counts. However, it requires holding the complete vocabulary in memory, we can't use the CountVectorizer for out-of-core learning.
Similarly, since the TfidfVectorizer needs to keep the all feature vectors of the training dataset in memory to calculate the inverse document frequencies, for out-of-core learning, we'll use another vectorizer called HashingVectorizer for text processing:

This text vectorizer implementation uses the hashing trick to find the token string name to feature integer index mapping.
This strategy has several advantages:
- It is very low memory scalable to large datasets as there is no need to store a vocabulary dictionary in memory.
- It is fast to pickle and un-pickle as it holds no state besides the constructor parameters.
- Itt can be used in a streaming (partial fit) or parallel pipeline as there is no state computed during fit.
However, there are also a couple of cons (vs using a CountVectorizer with an in-memory vocabulary):
- There is no way to compute the inverse transform (from feature indices to string feature names) which can be a problem when trying to introspect which features are most important to a model.
- There can be collisions: distinct tokens can be mapped to the same feature index. However in practice this is rarely an issue if n_features is large enough (e.g. $2^{18}$ for text classification problems).
- No IDF weighting as this would render the transformer stateful.
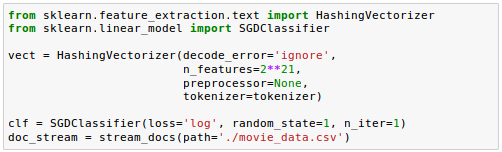
In the code, we initialized HashingVectorizer with our tokenizer function and set the number of features to $2^{21}$.
Also, we reinitialized a logistic regression classifier by setting the loss parameter of the SGDClassifier to log. Note that the default is set to 'hinge' which gives a linear SVM. The log loss gives logistic regression, a probabilistic classifier:

By choosing a large number of features in the HashingVectorizer, we reduce the chance to cause hash collisions but we also increase the number of coefficients in our logistic regression model.
Now we set up all the necessary functions, we can now start the out-of-core learning using the code as the following:
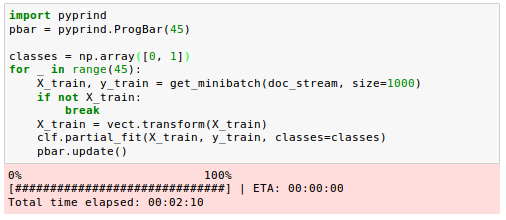
In the for loop, we iterated over 45 minibatches of documents where each minibatch consists of 1,000 documents each.
Since we completed the incremental learning process, we will use the last 5,000 documents to evaluate the performance of our model:

As we can see from the output, the accuracy of the model is 88 percent, 2% below the accuracy that we achieved in the last article which used the grid search for hyperparameter tuning.
Considering the computing time it took to complete, however, we can clearly see out-of-core learning is very memory-efficient.
Now we want to update our model using the last 5,000 documents:

Github Jupyter notebook is available from Sentiment Analysis
"Python Machine Learning" by Sebastian Raschka
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization