Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis III
In my previous article (Machine Learning (Natural Language Processing - NLP) : Sentiment Analysis II), we learned about the tokenization via stemmer and stop-words.
In this article, we are going to train a logistic regression model for document classification.
Natural Language Processing (NLP): Sentiment Analysis I (IMDb & bag-of-words)
Natural Language Processing (NLP): Sentiment Analysis II (tokenization, stemming, and stop words)
Natural Language Processing (NLP): Sentiment Analysis III (training & cross validation)
Natural Language Processing (NLP): Sentiment Analysis IV (out-of-core)
We're now almost ready to classify the movie reviews into positive and negative reviews.
First of all, we want to divide the DataFrame data which we cleaned-up in previous articles into 25,000/25,000 documents for training/testing:

Next, using 5-fold stratified cross-validation, we will use a GridSearchCV object to find the optimal set of parameters for our logistic regression model:

The sklearn.model_selection.GridSearchCV returns training score after exhaustive search over specified parameter values for an estimator. It implements a "fit" and a "score" method which we are going to use once the grid search finish.
It also implements "predict", "predict_proba", "decision_function", "transform" and "inverse_transform" if they are implemented in the estimator used:

The parameters of the estimator used to apply these methods are optimized by cross-validated grid-search over a parameter grid.
Here is the full code:
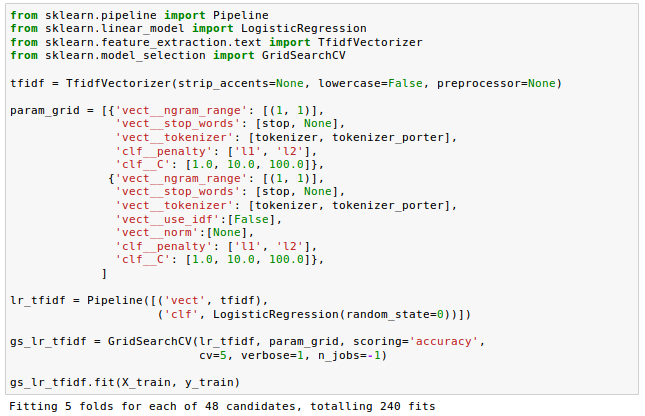
In the code we're using the TfidfVectorizer instead of CountVectorizer and TfidfTransformer.
The param_grid consisted of two parameter dictionaries:
- For the first dictionary, we used the TfidfVectorizer with its default settings (use_idf=True, smooth_idf=True, and norm='l2') to calculate the tf-idfs.
- For the second dictionary, we set those parameters to use_idf=False, smooth_idf=False, and norm=None in order to train a model based on raw term frequencies.
Regarding the logistic regression classifier itself, we trained models using L2 and L1 regularization via the penalty parameter and compared different regularization strengths by defining a range of values for the inverse-regularization parameter C.
Note that we used integer value of 5 for cv which determines the cross-validation splitting strategy. If None is given, the default is 3-fold cross validation will be used.
Because the number of feature vectors and vocabularies make the grid search computationally quite expensive, we restricted ourselves to a limited number of parameter combinations when we initialize the GridSearchCV object and its parameter grid.
Depending on th computer, it may take up to couple of hours.
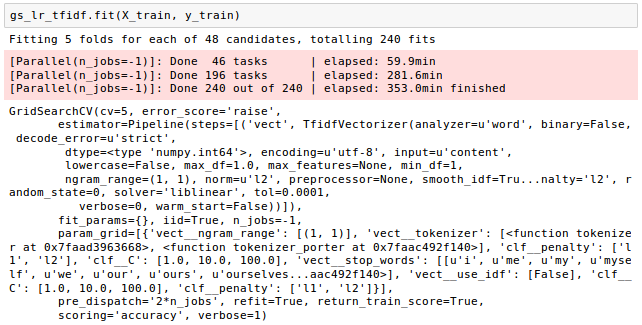
Once the grid search has finished, we can print the best parameter set which gave the best results on the hold out data:
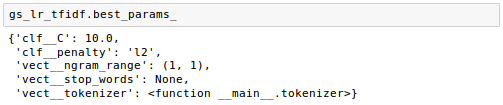
From the output, we got the best grid search results using the regular tokenizer without Porter stemming nor stop-word library. The tf-idfs we got uses the combination of a logistic regression classifier with L2 regularization of the regularization strength C=10.0.
Using the best model from the grid search, we can get the output for the 5-fold cross-validation accuracy scores on the training set and the classification accuracy on the test dataset:
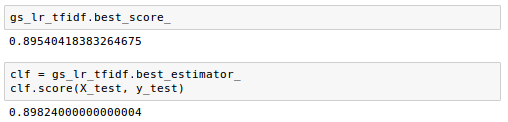
Here the best_estimator_ is the estimator that was chosen by the search, i.e. estimator which gave highest score on the left out data and the best_score_ is the score of best_estimator on the left out data.
The output shows us that our machine learning model can predict whether a movie review is positive or negative with almost 90 percent accuracy.
In the previous secion, the best_score_ attribute returns the average score over the 5-folds of the best model since we used cv=5 for GridSearchCV().
In this section, we'll illustrate how the cross-validation works via a simple data set of random integers that represent our class labels. We'll compare GridSearchCV() with StratifiedKFold().
Here is the code to generate the simple dataset:
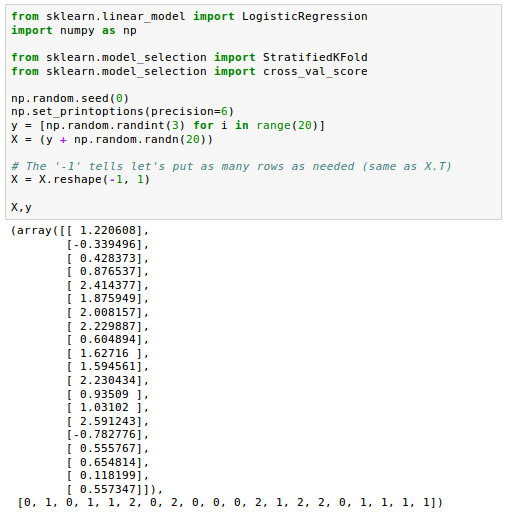
Now we're going to make cross-validation object is a variation of KFold that returns stratified folds using sklearn.model_selection.StratifiedKFold() which is defined as the following:

Let's run it on our sample data:
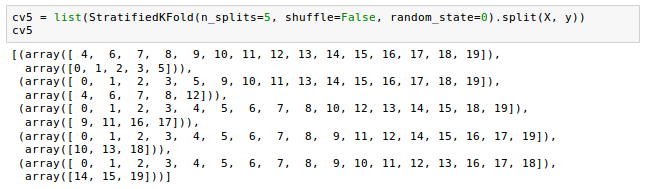
It will generate indices to split data into training and test set. Note that we used split(X, y) method on the output.
To evaluate a score by cross-validation, we'll use sklearn.model_selection.cross_val_score() which is defined as the following:
We get the following output if we run it:

We fed the indices of 5 cross-validation folds (cv3) to the cross_val_score scorer(). It returned 5 accuracy scores for the 5 test folds.
Now, we'll use the GridSearchCV for exhaustive search over specified parameter values for an LogisticRegression estimator and feed it the same 5 cross-validation sets via the pre-generated cv3 indices:
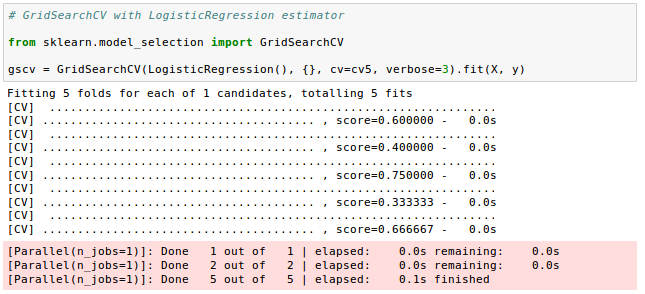
From the output we can see the scores for the 5 folds are exactly the same as the ones from cross_val_score via StratifiedKFold().
How about the score? Will it be the same?
The bestscore attribute of the GridSearchCV object is available only after fitting, so it now just returns the average accuracy score of the best model:

Let's compare it with the average score computed the cross_val_score:

As we can see, the result are indeed consistent!
Github Jupyter notebook is available from Sentiment Analysis
"Python Machine Learning" by Sebastian Raschka
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization