Google page ranking by keywords - 2020
In this chapter, I made a simple tool for getting the page rank for given keywords.
The required inputs are:
- site (domain) name such as "example.com"
- keywords such as "python map"
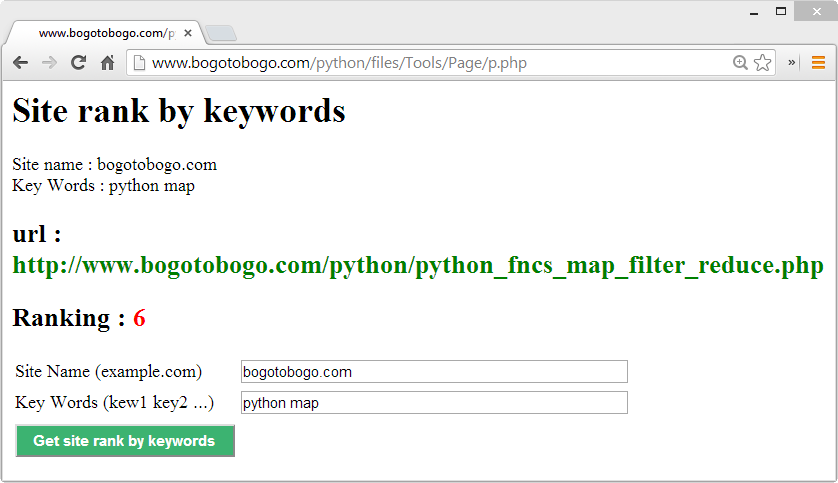
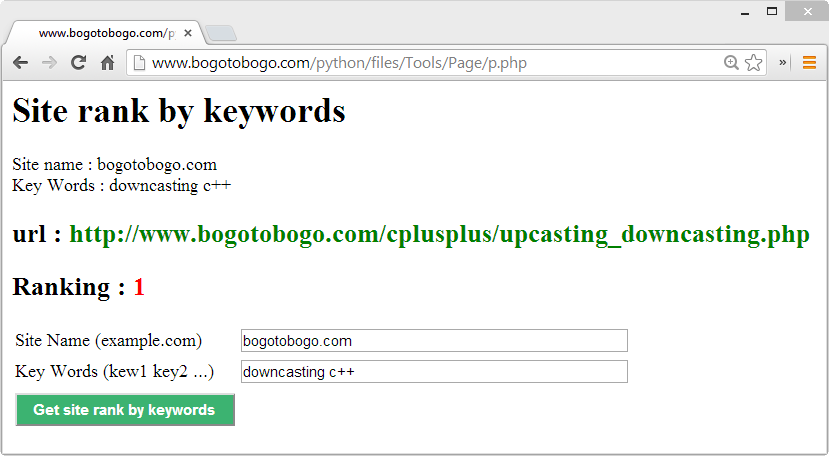
We can test it from Get site rank by keywords.
Usually, google search displays 10 site per page, so if the rank is 24th, then it actually shows up on the 4th of the 3rd page of the google search.
I used two files:
Since the two codes below are almost self explanatory, I'll skip detailed description. Later, if I could find some time, I'll put more lines here.
<html>
<body>
<?php
if(isset($_POST['submit_button']))
{
$site = $_POST['site'];
$keywords = $_POST['keywords'];
$output = exec("python page.py $site $keywords");
#echo "<h1>Output from python: $output</h1>";
echo "<h1>Site rank by keywords </h1>";
$s = preg_split('/\s+/', $output); // spacing as a delimiter
$rank = $s[1];
$url_found = $s[0];
echo "Site name : $site <br>";
echo "Key Words : $keywords<br>";
echo "<h2>url : <font color='green'><b>$url_found</b></font><br></h2>";
if($rank != -1)
echo "<h2>Ranking : <font color='red'><b>$rank</b></font><br></h2>";
else
echo "<h2>Ranking : <font color='red'><b>not within 100th</b></font><br></h2>";
}
?>
<form method="post" action="<?php echo $_SERVER['PHP_SELF']; ?>">
<table border="0">
<tr>
<td width="200">Site Name (example.com)</td>
<td width="300">
<input type="text" value="<?php if($site) {echo $site; } ?>"
name="site" size="50" maxlength="300"/>
</td>
</tr>
<tr>
<td width="200">Key Words (kew1 key2 ...)</td>
<td width="300">
<input type="text" value="<?php if($keywords) {echo $keywords; } ?>"
name="keywords" size="50" maxlength="500"/>
</td>
</tr>
<tr>
<td></td>
</tr>
<tr>
<td>
<input type="submit" name="submit_button" value="Get site rank by keywords"
style="background:mediumseagreen; color:#ffffff; font-weight:bold;
width:200px; height:30px"/>
</td>
<td></td> <td></td> <td></td> <td></td>
</tr>
</table>
</form>
<?php
$site = $_POST['site'];
$keywords = $_POST['keywords'];
?>
</html>
#!/usr/bin/python
"""
Google AJAX Search Module
http://code.google.com/apis/ajaxsearch/documentation/reference.html
"""
try:
import simplejson as json
except:
import json
import urllib
URL = '//ajax.googleapis.com/ajax/services/search/web?'
#Web Search Specific Arguments
#http://code.google.com/apis/ajaxsearch/documentation/reference.html#_fonje_web
#SAFE,FILTER
"""
SAFE
This optional argument supplies the search safety level which may be one of:
* safe=active - enables the highest level of safe search filtering
* safe=moderate - enables moderate safe search filtering (default)
* safe=off - disables safe search filtering
"""
SAFE_ACTIVE = "active"
SAFE_MODERATE = "moderate"
SAFE_OFF = "off"
"""
FILTER
This optional argument controls turning on or off the duplicate content filter:
* filter=0 - Turns off the duplicate content filter
* filter=1 - Turns on the duplicate content filter (default)
"""
FILTER_OFF = 0
FILTER_ON = 1
#Standard URL Arguments
#http://code.google.com/apis/ajaxsearch/documentation/reference.html#_fonje_args
"""
RSZ
This optional argument supplies the number of results that the application would like to receive.
A value of small indicates a small result set size or 4 results.
A value of large indicates a large result set or 8 results. If this argument is not supplied, a value of small is assumed.
"""
RSZ_SMALL = "small"
RSZ_LARGE = "large"
"""
HL
This optional argument supplies the host language of the application making the request.
If this argument is not present then the system will choose a value based on the value of the Accept-Language http header.
If this header is not present, a value of en is assumed.
"""
class pygoogle2:
def __init__(self, query, site="google.com", pages=13,hl='en'):
self.pages = pages #Number of pages. default 13
self.query = query #query string, keywords
self.url_found = 'none' #url found from search, default='none'
self.site = site #site name. default "google.com"
self.filter = FILTER_ON #Controls turning on or off the duplicate content filter. On = 1.
self.rsz = RSZ_LARGE #Results per page. small = 4 /large = 8
self.safe = SAFE_OFF #SafeBrowsing - active/moderate/off
self.hl = hl #Defaults to English (en)
self.found_it = False #if query is successful, it will be set to True
self.ranking = -1 #if found, the will get the rank
#print "self.site=%s self.query=%s"%(self.site, self.query)
def __search__(self,print_results = False):
results = []
for page in range(0,self.pages):
rsz = 8
if self.rsz == RSZ_SMALL:
rsz = 4
args = {'q' : self.query,
'v' : '1.0',
'start' : page*rsz,
'rsz': self.rsz,
'safe' : self.safe,
'filter' : self.filter,
'hl' : self.hl
}
q = urllib.urlencode(args)
search_results = urllib.urlopen(URL+q)
data = json.loads(search_results.read())
item_count = 0 # rank of the result
page_count = page + 1 # 'cause page starts from 0
if print_results:
if data['responseStatus'] == 200:
for result in data['responseData']['results']:
if result:
item_count += 1
#print '[%s]'%(urllib.unquote(result['titleNoFormatting']))
#print result['content'].strip("<b>...</b>").replace("<b>",'').replace("</b>",'').replace("'","'").strip()
#print urllib.unquote(result['unescapedUrl'])+'\n'
# found!!
if result['unescapedUrl'].find(site) != -1:
self.ranking = page*rsz + item_count
print "Found!!!!!! ranking = %s" %(self.ranking)
self.found_it = True
if self.found_it == True:
self.url_found = result['unescapedUrl']
print "***url_found=%s" %(self.url_found)
break
results.append(data)
if self.found_it == True:
break;
return results
def search(self):
"""Returns a dict of Title/URLs"""
print "Returns a dict of Title/URLs"
results = {}
for data in self.__search__():
for result in data['responseData']['results']:
if result:
title = urllib.unquote(result['titleNoFormatting'])
results[title] = urllib.unquote(result['unescapedUrl'])
return results
def search_page_wise(self):
"""Returns a dict of page-wise urls"""
results = {}
for page in range(0,self.pages):
args = {'q' : self.query,
'v' : '1.0',
'start' : page,
'rsz': RSZ_LARGE,
'safe' : SAFE_OFF,
'filter' : FILTER_ON,
}
q = urllib.urlencode(args)
search_results = urllib.urlopen(URL+q)
data = json.loads(search_results.read())
urls = []
for result in data['responseData']['results']:
if result:
url = urllib.unquote(result['unescapedUrl'])
urls.append(url)
results[page] = urls
return results
def get_urls(self):
"""Returns list of result URLs"""
results = []
for data in self.__search__():
for result in data['responseData']['results']:
if result:
results.append(urllib.unquote(result['unescapedUrl']))
return results
def get_result_count(self):
"""Returns the number of results"""
print "Returns the number of results"
temp = self.pages
#self.pages = 1
result_count = 0
try:
result_count = self.__search__(True)[0]['responseData']['cursor']['estimatedResultCount']
except Exception,e:
print e
finally:
self.pages = temp
return result_count
def display_results(self):
"""Prints results (for command line)"""
self.__search__(True)
"""
Sample command :
python page.py stackoverflow.com multithreading
Sample output: rank url
10 http://stackoverflow.com/questions/tagged/multithreading
"""
if __name__ == "__main__":
import sys
site = sys.argv[1]
query = ' '.join(sys.argv[2:])
print "query=%s"%(query)
g = pygoogle2(query, site)
print '*Found %s results*'%(g.get_result_count())
# This is the output
print g.url_found, g.ranking
#g.display_results()
For some reason, if we try several times consecutively without much time interval, we may not get any results for the ranking. Not sure whether it's a bug in my code or google's blocking such quick paced tries.
If that happens, we may want to take some time, and then try. Then, it will start to work again. Odd!
Python tutorial
Python Home
Introduction
Running Python Programs (os, sys, import)
Modules and IDLE (Import, Reload, exec)
Object Types - Numbers, Strings, and None
Strings - Escape Sequence, Raw String, and Slicing
Strings - Methods
Formatting Strings - expressions and method calls
Files and os.path
Traversing directories recursively
Subprocess Module
Regular Expressions with Python
Regular Expressions Cheat Sheet
Object Types - Lists
Object Types - Dictionaries and Tuples
Functions def, *args, **kargs
Functions lambda
Built-in Functions
map, filter, and reduce
Decorators
List Comprehension
Sets (union/intersection) and itertools - Jaccard coefficient and shingling to check plagiarism
Hashing (Hash tables and hashlib)
Dictionary Comprehension with zip
The yield keyword
Generator Functions and Expressions
generator.send() method
Iterators
Classes and Instances (__init__, __call__, etc.)
if__name__ == '__main__'
argparse
Exceptions
@static method vs class method
Private attributes and private methods
bits, bytes, bitstring, and constBitStream
json.dump(s) and json.load(s)
Python Object Serialization - pickle and json
Python Object Serialization - yaml and json
Priority queue and heap queue data structure
Graph data structure
Dijkstra's shortest path algorithm
Prim's spanning tree algorithm
Closure
Functional programming in Python
Remote running a local file using ssh
SQLite 3 - A. Connecting to DB, create/drop table, and insert data into a table
SQLite 3 - B. Selecting, updating and deleting data
MongoDB with PyMongo I - Installing MongoDB ...
Python HTTP Web Services - urllib, httplib2
Web scraping with Selenium for checking domain availability
REST API : Http Requests for Humans with Flask
Blog app with Tornado
Multithreading ...
Python Network Programming I - Basic Server / Client : A Basics
Python Network Programming I - Basic Server / Client : B File Transfer
Python Network Programming II - Chat Server / Client
Python Network Programming III - Echo Server using socketserver network framework
Python Network Programming IV - Asynchronous Request Handling : ThreadingMixIn and ForkingMixIn
Python Coding Questions I
Python Coding Questions II
Python Coding Questions III
Python Coding Questions IV
Python Coding Questions V
Python Coding Questions VI
Python Coding Questions VII
Python Coding Questions VIII
Python Coding Questions IX
Python Coding Questions X
Image processing with Python image library Pillow
Python and C++ with SIP
PyDev with Eclipse
Matplotlib
Redis with Python
NumPy array basics A
NumPy Matrix and Linear Algebra
Pandas with NumPy and Matplotlib
Celluar Automata
Batch gradient descent algorithm
Longest Common Substring Algorithm
Python Unit Test - TDD using unittest.TestCase class
Simple tool - Google page ranking by keywords
Google App Hello World
Google App webapp2 and WSGI
Uploading Google App Hello World
Python 2 vs Python 3
virtualenv and virtualenvwrapper
Uploading a big file to AWS S3 using boto module
Scheduled stopping and starting an AWS instance
Cloudera CDH5 - Scheduled stopping and starting services
Removing Cloud Files - Rackspace API with curl and subprocess
Checking if a process is running/hanging and stop/run a scheduled task on Windows
Apache Spark 1.3 with PySpark (Spark Python API) Shell
Apache Spark 1.2 Streaming
bottle 0.12.7 - Fast and simple WSGI-micro framework for small web-applications ...
Flask app with Apache WSGI on Ubuntu14/CentOS7 ...
Fabric - streamlining the use of SSH for application deployment
Ansible Quick Preview - Setting up web servers with Nginx, configure enviroments, and deploy an App
Neural Networks with backpropagation for XOR using one hidden layer
NLP - NLTK (Natural Language Toolkit) ...
RabbitMQ(Message broker server) and Celery(Task queue) ...
OpenCV3 and Matplotlib ...
Simple tool - Concatenating slides using FFmpeg ...
iPython - Signal Processing with NumPy
iPython and Jupyter - Install Jupyter, iPython Notebook, drawing with Matplotlib, and publishing it to Github
iPython and Jupyter Notebook with Embedded D3.js
Downloading YouTube videos using youtube-dl embedded with Python
Machine Learning : scikit-learn ...
Django 1.6/1.8 Web Framework ...
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization