Shallow parsing / chunking
NLTK Tutorials
Introduction - Install NLTKTokenizing and Tagging
Stemming
Chunking
tf-idf
Chunking (aka. Shallow parsing) is to analyzing a sentence to identify the constituents (noun groups, verbs, verb groups, etc.). However, it does not specify their internal structure, nor their role in the main sentence.
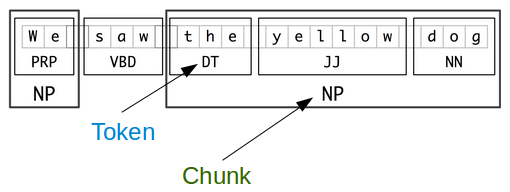
Picture from http://www.nltk.org/book/ch07.html
"The smaller boxes show the word-level tokenization and part-of-speech tagging, while the large boxes show higher-level chunking. Each of these larger boxes is called a chunk. Like tokenization, which omits whitespace, chunking usually selects a subset of the tokens. Also like tokenization, the pieces produced by a chunker do not overlap in the source text." - from http://www.nltk.org/book/ch07.html
When we try to do chunking, we may get the error like this:
LookupError: ********************************************************************** Resource 'chunkers/maxent_ne_chunker/english_ace_multiclass.pickle' not found. Please use the NLTK Downloader to obtain the resource: >>> nltk.download()
So, we need to download 'maxent_ne_chunker' and 'words':
>>> nltk.download('maxent_ne_chunker')
[nltk_data] Downloading package 'maxent_ne_chunker' to
[nltk_data] /home/k/nltk_data...
[nltk_data] Unzipping chunkers/maxent_ne_chunker.zip.
True
>>> nltk.download('words')
[nltk_data] Downloading package 'words' to /home/k/nltk_data...
[nltk_data] Unzipping corpora/words.zip.
True
Here is the code for chunking:
import nltk
if __name__ == "__main__":
sentence = "We saw the yellow dog"
tokens = nltk.word_tokenize(sentence)
print("tokens = %s") %(tokens)
tagged = nltk.pos_tag(tokens)
entities = nltk.chunk.ne_chunk(tagged)
print("entities = %s") %(entities)
Output:
tokens = ['We', 'saw', 'the', 'yellow', 'dog'] entities = (S We/PRP saw/VBD the/DT yellow/JJ dog/NN)
We need the following packages:
>>> nltk.download('maxent_treebank_pos_tagger')
>>> nltk.download('treebank')
We may also need Tkinter:
sudo apt-get install python-tk
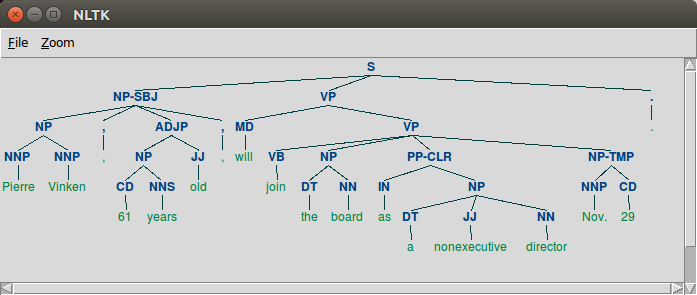
The code:
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization