Tutorial: GIT and GitHub Terminologies - 2020
This Git terminology is a compiled work mostly based on http://git-scm.com/.
- branch
A branch in Git is simply a lightweight movable pointer to a commit. - checkout
To switch to an existing branch, we run thegit checkoutcommand. - fetch
To synchronize our work withremote/origin, we run agit fetch origincommand. - HEAD
In Git,HEADis a pointer to the local branch we're currently on. - master
Masteris the default branch name in Git. - origin
originis the default name for a remote when we rungit clone. - pull
git pullis essentially (git fetch+git merge). - upstream branch
Upstream branch (tracking branch)is a local branch that has a direct relationship to a remote branch.
A branch in Git is simply a lightweight movable pointer to a commit. The default branch name in Git is master. As we start making commits, we're given a master branch that points to the last commit we made. Every time we commit, it moves forward automatically.
If we want to make a new branch called testing, we do:
$ git branch testing
The git branch command only created a new branch, and it didn't switch to that branch.
Because a branch in Git is in actuality a simple file that contains the 40 character SHA-1 checksum of the commit it points to, branches are cheap to create and destroy. Creating a new branch is as quick and simple as writing 41 bytes to a file (40 characters and a newline).
This is in sharp contrast to the way most older VCS tools branch, which involves copying all of the project's files into a second directory. This can take several seconds or even minutes, depending on the size of the project, whereas in Git the process is always instantaneous. Also, because we're recording the parents when we commit, finding a proper merge base for merging is automatically done for us and is generally very easy to do. These features help encourage developers to create and use branches often.
See checkout.
Here is current status of our git:
$ git log --oneline --decorate fd9c51d (HEAD, master) update1 6fc4a18 initial commit
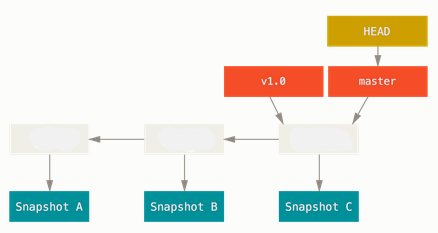
Let's make another branch called 'testing':
$ git branch testing $ git log --oneline --decorate fd9c51d (HEAD, testing, master) update1 6fc4a18 initial commit
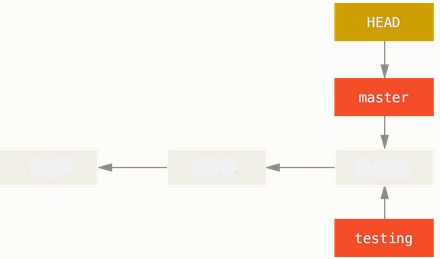
To switch to an existing branch, we run the git checkout command.
Let's switch to the new 'testing' branch:
$ git checkout testing Switched to branch 'testing' $ git log --oneline --decorate fd9c51d (HEAD, testing, master) update1 6fc4a18 initial commit
This moves HEAD to point to the testing branch.
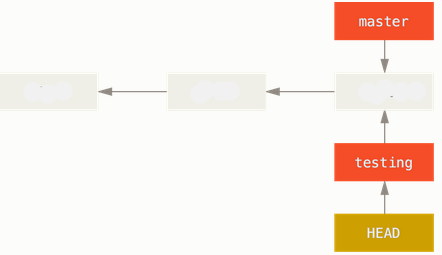
If we make a commit to the 'testing' branch, the HEAD will point to a new snapshot:
$ vi README $ git add README $ git commit -m "update2" [testing 1357337] update2 1 file changed, 1 insertion(+), 1 deletion(-) $ git log --oneline --decorate 1357337 (HEAD, testing) update2 fd9c51d (master) update1 6fc4a18 initial commit
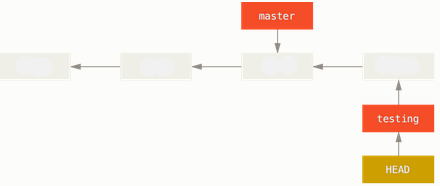
Now our testing branch has moved forward, but our master branch still points to the commit we were on when weu ran git checkout to switch branches.
Let's switch back to the master branch:
$ git checkout master Switched to branch 'master' $ git log --oneline --decorate fd9c51d (HEAD, master) update1 6fc4a18 initial commit
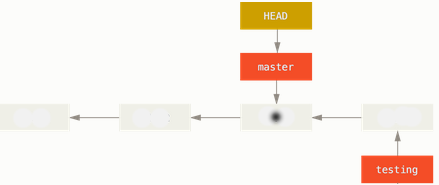
That command did two things. It moved the HEAD pointer back to point to the master branch, and it reverted the files in our working directory back to the snapshot that master points to. This also means the changes we make from this point forward will diverge from an older version of the project. It essentially rewinds the work we've done in our testing branch so we can go in a different direction.
Note: Switching branches changes files in our working directory
It's important to note that when we switch branches in Git, files in our working directory will change. If we switch to an older branch, our working directory will be reverted to look like it did the last time we committed on that branch. If Git cannot do it cleanly, it will not let us switch at all. It's best to have a clean working state when we switch branches. However, if we've committed all our changes we can switch back to our master branch.
At this point, our project working directory is exactly the way it was. This is an important point to remember: when we switch branches, Git resets our working directory to look like it did the last time we committed on that branch. It adds, removes, and modifies files automatically to make sure our working copy is what the branch looked like on our last commit to it.
Now that we rolled back to older master, the 'README' file has the old update:
README update 1
Note that we've changed to 'update2' before, however, it's done on the 'testing' branch. Let's make some changes in this master branch that's been reverted:
README update 1->2
Then, do git commit:
$ git commit -a -m 'made changes again 1->2' [master aec8024] made changes again 1->2 1 file changed, 1 insertion(+), 1 deletion(-)
To check where is our HEAD:
$ git log --oneline --decorate aec8024 (HEAD, master) made changes again 1->2 fd9c51d update1 6fc4a18 initial commit
The HEAD stays at the old reverted master:
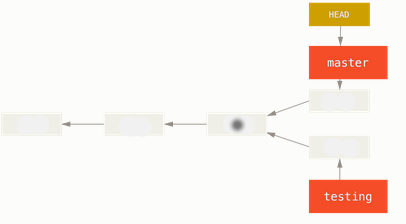
Now our project history has diverged. We created and switched to a branch, did some work on it, and then switched back to our main branch and did other work. Both of those changes are isolated in separate branches: we can switch back and forth between the branches and merge them together when we're ready. And we did all that with simple branch, checkout, and commit commands.
If we use git log with more flag such as --graph --all, we can see the history of our commits, showing where our branch pointers are and how our history has diverged.
$ git log --oneline --decorate --graph --all * aec8024 (HEAD, master) made changes again 1->2 | * 1357337 (testing) update2 |/ * fd9c51d update1 * 6fc4a18 initial commit
To synchronize our work with remote/origin, we run a git fetch origin command.
Our local and remote work can diverge as shown below:
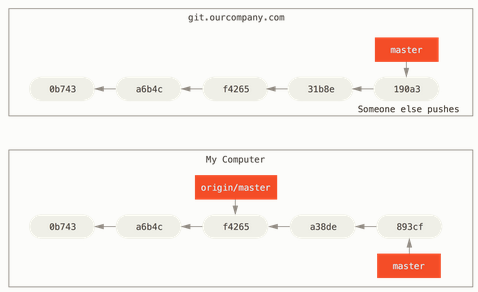
Suppose we do some work on our local master branch, and, in the meantime, someone else pushes to 'git.ourcompany.com' and updates its master branch, then our histories move forward differently. Also, as long as we stay out of contact with our origin server, our origin/master pointer doesn't move.
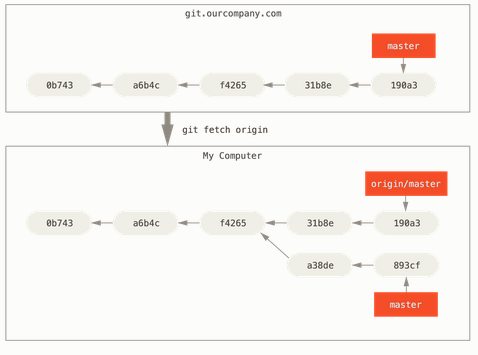
So, we need to synchronize our work with remote/origin. To do that we run a git fetch origin command. This command looks up which server origin is (in our case, it's 'git.ourcompany.com'), fetches any data from it that we don't yet have, and updates our local database, moving our origin/master pointer to its new, more up-to-date position:
HEAD is a pointer to the local branch we're currently on.
The git branch command only created a new branch, and it didn't switch to that branch:
$ git log --oneline --decorate fd9c51d (HEAD, master) update1 6fc4a18 initial commit $ git branch testing $ git log --oneline --decorate fd9c51d (HEAD, testing, master) update1 6fc4a18 initial commit
See checkout.
Master is a default branch name in Git. A branch in Git is simply a lightweight movable pointer to a commit.
The master branch in Git is not a special branch. It is exactly like any other branch. The only reason nearly every repository has one is that the git init command creates it by default and most people don't bother to change it.
See checkout.
origin is the default name for a remote when we run git clone.
Suppose we have a Git server on our network at 'git.ourcompany.com'. If we clone from this, Git's clone command automatically names it origin for us, pulls down all its data, creates a pointer to where its master branch is, and names it origin/master locally. Git also gives us our own local master branch starting at the same place as origin's master branch, so we have something to work from.
origin is not special:
Just like the branch name master does not have any special meaning in Git, neither does origin. While master is the default name for a starting branch when we run git init which is the only reason it's widely used, origin is the default name for a remote when we run git clone. If we run git clone -o foo instead, then we will have foo/master as our default remote branch.
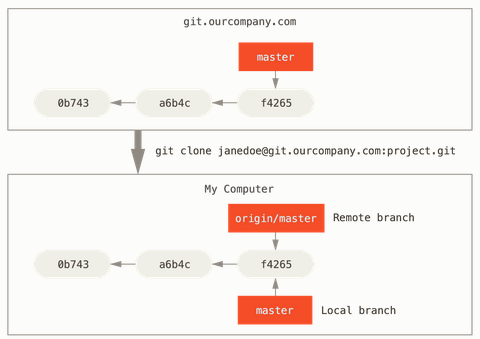
Note that our local and remote work can diverge.
Suppose we do some work on our local master branch, and, in the meantime, someone else pushes to 'git.ourcompany.com' and updates its master branch, then our histories move forward differently. Also, as long as we stay out of contact with our origin server, our origin/master pointer doesn't move.
To see how to synchronize our local work with remote/origin, go to fetch.
git pull is essentially a git fetch + git merge.
While the git fetch command will fetch down all the changes on the server that we don't have yet, it will not modify our working directory at all. It will simply get the data for us and let us merge it ourselves. However,
git pull is essentially a git fetch immediately followed by a git merge in most cases. git pull will look up what server and branch our current branch is tracking, fetch from that server and then try to merge in that remote branch.
Generally it's better to simply use the fetch and merge commands explicitly as the magic of git pull can often be confusing.
Upstream branch (tracking branch) is a local branch that has a direct relationship to a remote branch.
Checking out a local branch from a remote branch automatically creates what is called a tracking branch (or sometimes an upstream branch). Tracking branches are local branches that have a direct relationship to a remote branch. If we're on a tracking branch and type git pull, Git automatically knows which server to fetch from and branch to merge into.
When we clone a repository, it generally automatically creates a master branch that tracks origin/master.
Git/GitHub Tutorial
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization