Spark 1.2 using VirtualBox and QuickStart VM : wordcount
Hadoop MapReduce is slow due to replication, serialization, and disk IO. It is inefficient for interactive algorithms such as Machine learning, Graphs, and Network analysis. Also, it's not ideal for interactive data mining such as R, Adhoc Reporting, and searching.
Because of In-memory processing, Spark's computations are very fast. Developers can write iterative algorithms without writing out a result set after each pass through the data. It also provides an integrated framework for advanced analytics like Graph processing, Streaming processing, Machine learning, etc. This can simplify integration.

Picture source: 2015 Typesafe survey.
Spark extends the popular MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. Speed is important in processing large datasets, as it means the difference between exploring data interactively and waiting minutes or hours. One of the main features Spark offers for speed is the ability to run computations in memory, but the system is also more efficient than MapReduce for complex applications running on disk.
Still, it's comparatively newer than Hadoop and has only few users.
According to https://spark.apache.org/, Apache Spark has the following advantages:
- Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Spark has an advanced directed acyclic graph (DAG) execution engine that supports cyclic data flow and in-memory computing. - Ease of Use
Write applications quickly in Java, Scala or Python.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And we can use it interactively from the Scala and Python shells. - Generality
Combine SQL, streaming, and complex analytics.
Spark powers a stack of high-level tools including Spark SQL, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application. - Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, S3.
Our example app is another version of WordCount, the classic MapReduce example. In WordCount, the goal is to learn the distribution of letters in the most popular words in our corpus. In other words, we may want to:
- Read an input set of text documents.
- Count the number of times each word appears.
- Filter out all words that show up less than a million times.
- For the remaining set, count the number of times each letter occurs.
In MapReduce, this would require two MapReduce jobs, as well as persisting the intermediate data to HDFS in between them. However, in Spark, we can write a single job in about 90 percent fewer lines of code.
In this chapter, we'll run Spark 1.2 with CDH 5.3 via Maven. The reference used are:
- How-to: Run a Simple Apache Spark App in CDH 5
- https://github.com/sryza/simplesparkapp
- Learning Spark - Lightning-fast Data Analysis, 2015
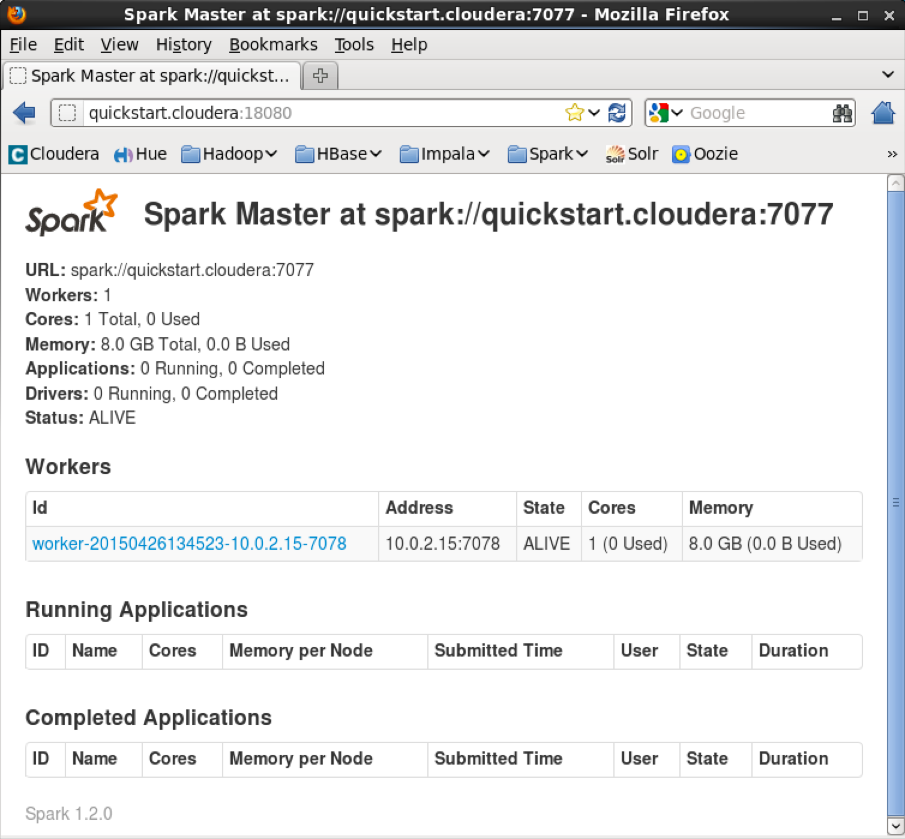
Here is the /etc/spark/con/spark-env.sh that comes with QuickStartVM:
#!/usr/bin/env bash
##
# Generated by Cloudera Manager and should not be modified directly
##
export SPARK_HOME=/usr/lib/spark
export STANDALONE_SPARK_MASTER_HOST=quickstart.cloudera
export SPARK_MASTER_PORT=7077
export DEFAULT_HADOOP_HOME=/usr/lib/hadoop
### Path of Spark assembly jar in HDFS
export SPARK_JAR_HDFS_PATH=${SPARK_JAR_HDFS_PATH:-/user/spark/share/lib/spark-assembly.jar}
### Let's run everything with JVM runtime, instead of Scala
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_IP=$STANDALONE_SPARK_MASTER_HOST
export HADOOP_HOME=${HADOOP_HOME:-$DEFAULT_HADOOP_HOME}
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
[cloudera@quickstart ~]$ hadoop fs -ls /user Found 9 items drwxr-xr-x - cloudera cloudera 0 2015-03-30 15:35 /user/cloudera drwxr-xr-x - flume flume 0 2015-04-01 19:25 /user/flume drwxr-xr-x - hdfs supergroup 0 2015-04-05 11:11 /user/hdfs drwxr-xr-x - mapred hadoop 0 2015-03-15 14:08 /user/history drwxrwxrwx - hive hive 0 2014-12-18 04:33 /user/hive drwxrwxr-x - hue hue 0 2015-03-21 15:34 /user/hue drwxrwxrwx - oozie oozie 0 2014-12-18 04:34 /user/oozie drwxr-xr-x - sample sample 0 2015-03-14 22:05 /user/sample drwxr-xr-x - spark spark 0 2014-12-18 04:34 /user/spark
package org.apache.spark.examples;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.*;
import org.apache.spark.SparkConf;
import scala.Tuple2;
public class JavaWordCount {
public static void main(String[] args) {
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("Spark Count"));
final int threshold = Integer.parseInt(args[1]);
// split each document into words
JavaRDD<String> tokenized = sc.textFile(args[0]).flatMap(
new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) {
return Arrays.asList(s.split(" "));
}
}
);
// count the occurrence of each word
JavaPairRDD<String, Integer> counts = tokenized.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<String, Integer>(s, 1);
}
}
).reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
}
);
// filter out words with less than threshold occurrences
JavaPairRDD<String, Integer> filtered = counts.filter(
new Function<Tuple2<String, Integer>, Boolean>() {
@Override
public Boolean call(Tuple2<String, Integer> tup) {
return tup._2() >= threshold;
}
}
);
// count characters
JavaPairRDD<Character, Integer> charCounts = filtered.flatMap(
new FlatMapFunction<Tuple2<String, Integer>, Character>() {
@Override
public Iterable<Character> call(Tuple2<String, Integer> s) {
Collection<Character> chars = new ArrayList<Character>(s._1().length());
for (char c : s._1().toCharArray()) {
chars.add(c);
}
return chars;
}
}
).mapToPair(
new PairFunction<Character, Character, Integer>() {
@Override
public Tuple2<Character, Integer> call(Character c) {
return new Tuple2<Character, Integer>(c, 1);
}
}
).reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
}
);
System.out.println(charCounts.collect());
}
}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>spark.examples</groupId>
<artifactId>javawordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>javawordcount</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.4.0</version>
</dependency>
</dependencies>
</project>

To generate our app jar, we simply run:
[cloudera@quickstart JavaWordCount]$ pwd /home/cloudera/workspace/JavaWordCount [cloudera@quickstart JavaWordCount]$ mvn package
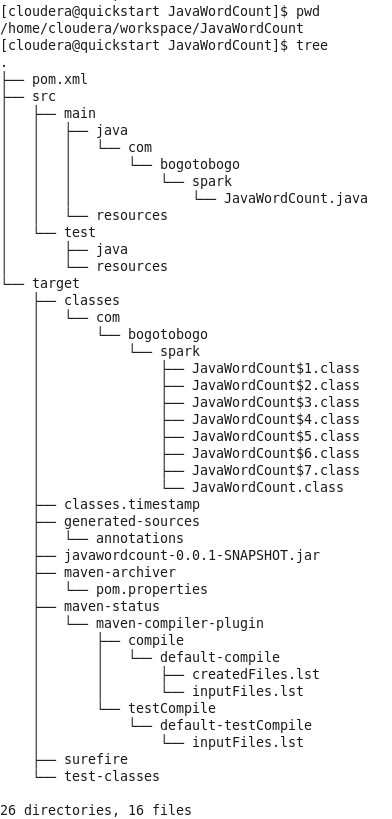
Here is the file structure provided by CDH5 QuickStartVM:
The input directory:
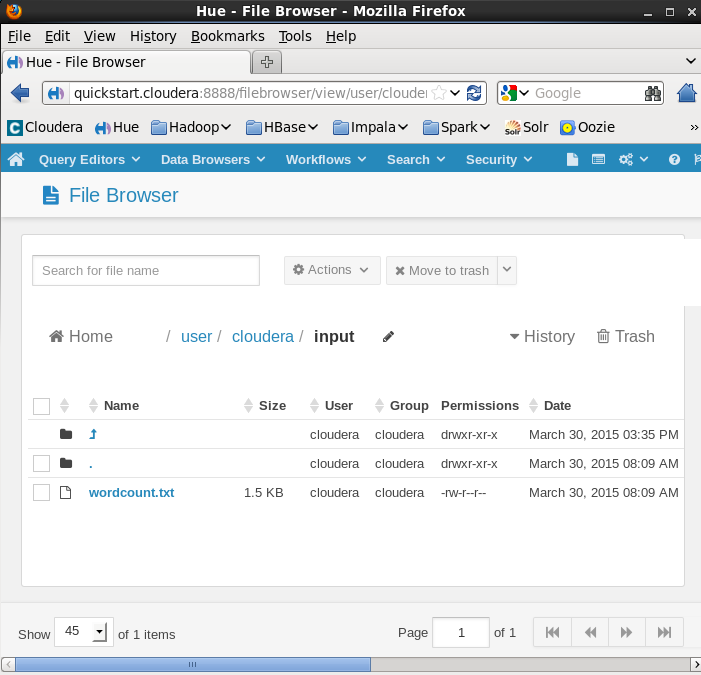
Before running, place the input file into a directory on HDFS. The repository supplies an example input file in its data directory. To run the Spark program, we use the spark-submit script:
[cloudera@quickstart JavaWordCount]$ spark-submit --class com.bogotobogo.spark.JavaWordCount --master local target/javawordcount-0.0.1-SNAPSHOT.jar input/wordcount.txt 2
The output from the run looks like this:
15/05/01 08:30:28 WARN Utils: Your hostname, quickstart.cloudera resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface eth0) 15/05/01 08:30:28 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address 15/05/01 08:30:28 INFO SecurityManager: Changing view acls to: cloudera 15/05/01 08:30:28 INFO SecurityManager: Changing modify acls to: cloudera 15/05/01 08:30:28 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(cloudera); users with modify permissions: Set(cloudera) 15/05/01 08:30:29 INFO Slf4jLogger: Slf4jLogger started 15/05/01 08:30:29 INFO Remoting: Starting remoting 15/05/01 08:30:29 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@10.0.2.15:48450] 15/05/01 08:30:29 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriver@10.0.2.15:48450] 15/05/01 08:30:29 INFO Utils: Successfully started service 'sparkDriver' on port 48450. 15/05/01 08:30:29 INFO SparkEnv: Registering MapOutputTracker 15/05/01 08:30:29 INFO SparkEnv: Registering BlockManagerMaster 15/05/01 08:30:29 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20150501083029-cecf 15/05/01 08:30:29 INFO MemoryStore: MemoryStore started with capacity 267.3 MB 15/05/01 08:30:30 INFO HttpFileServer: HTTP File server directory is /tmp/spark-a5c025c2-9b7f-48a4-914f-cac6f411f231 15/05/01 08:30:30 INFO HttpServer: Starting HTTP Server 15/05/01 08:30:30 INFO Utils: Successfully started service 'HTTP file server' on port 45085. 15/05/01 08:30:30 INFO Utils: Successfully started service 'SparkUI' on port 4040. 15/05/01 08:30:30 INFO SparkUI: Started SparkUI at http://10.0.2.15:4040 15/05/01 08:30:30 INFO SparkContext: Added JAR file:/home/cloudera/workspace/JavaWordCount/target/javawordcount-0.0.1-SNAPSHOT.jar at http://10.0.2.15:45085/jars/javawordcount-0.0.1-SNAPSHOT.jar with timestamp 1430494230600 15/05/01 08:30:30 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@10.0.2.15:48450/user/HeartbeatReceiver 15/05/01 08:30:30 INFO NettyBlockTransferService: Server created on 37295 15/05/01 08:30:30 INFO BlockManagerMaster: Trying to register BlockManager 15/05/01 08:30:30 INFO BlockManagerMasterActor: Registering block manager localhost:37295 with 267.3 MB RAM, BlockManagerId(, localhost, 37295) 15/05/01 08:30:30 INFO BlockManagerMaster: Registered BlockManager 15/05/01 08:30:32 INFO EventLoggingListener: Logging events to hdfs://quickstart.cloudera:8020/user/spark/applicationHistory/local-1430494230688 15/05/01 08:30:32 INFO MemoryStore: ensureFreeSpace(259846) called with curMem=0, maxMem=280248975 15/05/01 08:30:32 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 253.8 KB, free 267.0 MB) 15/05/01 08:30:32 INFO MemoryStore: ensureFreeSpace(21134) called with curMem=259846, maxMem=280248975 15/05/01 08:30:32 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.6 KB, free 267.0 MB) 15/05/01 08:30:32 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:37295 (size: 20.6 KB, free: 267.2 MB) 15/05/01 08:30:32 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0 15/05/01 08:30:32 INFO SparkContext: Created broadcast 0 from textFile at JavaWordCount.java:19 15/05/01 08:30:32 INFO FileInputFormat: Total input paths to process : 1 15/05/01 08:30:33 INFO SparkContext: Starting job: collect at JavaWordCount.java:83 15/05/01 08:30:33 INFO DAGScheduler: Registering RDD 3 (mapToPair at JavaWordCount.java:29) 15/05/01 08:30:33 INFO DAGScheduler: Registering RDD 7 (mapToPair at JavaWordCount.java:56) 15/05/01 08:30:33 INFO DAGScheduler: Got job 0 (collect at JavaWordCount.java:83) with 1 output partitions (allowLocal=false) 15/05/01 08:30:33 INFO DAGScheduler: Final stage: Stage 2(collect at JavaWordCount.java:83) 15/05/01 08:30:33 INFO DAGScheduler: Parents of final stage: List(Stage 1) 15/05/01 08:30:33 INFO DAGScheduler: Missing parents: List(Stage 1) 15/05/01 08:30:33 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[3] at mapToPair at JavaWordCount.java:29), which has no missing parents 15/05/01 08:30:33 INFO MemoryStore: ensureFreeSpace(4240) called with curMem=280980, maxMem=280248975 15/05/01 08:30:33 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 267.0 MB) 15/05/01 08:30:33 INFO MemoryStore: ensureFreeSpace(2480) called with curMem=285220, maxMem=280248975 15/05/01 08:30:33 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.4 KB, free 267.0 MB) 15/05/01 08:30:33 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:37295 (size: 2.4 KB, free: 267.2 MB) 15/05/01 08:30:33 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0 15/05/01 08:30:33 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:838 15/05/01 08:30:33 INFO DAGScheduler: Submitting 1 missing tasks from Stage 0 (MappedRDD[3] at mapToPair at JavaWordCount.java:29) 15/05/01 08:30:33 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 15/05/01 08:30:33 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 1388 bytes) 15/05/01 08:30:33 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 15/05/01 08:30:33 INFO Executor: Fetching http://10.0.2.15:45085/jars/javawordcount-0.0.1-SNAPSHOT.jar with timestamp 1430494230600 15/05/01 08:30:33 INFO Utils: Fetching http://10.0.2.15:45085/jars/javawordcount-0.0.1-SNAPSHOT.jar to /tmp/fetchFileTemp6146690575433412492.tmp 15/05/01 08:30:33 INFO Executor: Adding file:/tmp/spark-1972edea-edbb-4ccb-92d1-5ddb376207db/javawordcount-0.0.1-SNAPSHOT.jar to class loader 15/05/01 08:30:33 INFO HadoopRDD: Input split: hdfs://quickstart.cloudera:8020/user/cloudera/input/wordcount.txt:0+1539 15/05/01 08:30:33 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 15/05/01 08:30:33 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 15/05/01 08:30:33 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 15/05/01 08:30:33 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 15/05/01 08:30:33 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 15/05/01 08:30:33 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1895 bytes result sent to driver 15/05/01 08:30:33 INFO DAGScheduler: Stage 0 (mapToPair at JavaWordCount.java:29) finished in 0.570 s 15/05/01 08:30:33 INFO DAGScheduler: looking for newly runnable stages 15/05/01 08:30:33 INFO DAGScheduler: running: Set() 15/05/01 08:30:33 INFO DAGScheduler: waiting: Set(Stage 1, Stage 2) 15/05/01 08:30:33 INFO DAGScheduler: failed: Set() 15/05/01 08:30:33 INFO DAGScheduler: Missing parents for Stage 1: List() 15/05/01 08:30:33 INFO DAGScheduler: Missing parents for Stage 2: List(Stage 1) 15/05/01 08:30:33 INFO DAGScheduler: Submitting Stage 1 (MappedRDD[7] at mapToPair at JavaWordCount.java:56), which is now runnable 15/05/01 08:30:33 INFO MemoryStore: ensureFreeSpace(3680) called with curMem=287700, maxMem=280248975 15/05/01 08:30:33 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.6 KB, free 267.0 MB) 15/05/01 08:30:33 INFO MemoryStore: ensureFreeSpace(2037) called with curMem=291380, maxMem=280248975 15/05/01 08:30:33 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2037.0 B, free 267.0 MB) 15/05/01 08:30:33 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:37295 (size: 2037.0 B, free: 267.2 MB) 15/05/01 08:30:33 INFO BlockManagerMaster: Updated info of block broadcast_2_piece0 15/05/01 08:30:33 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 547 ms on localhost (1/1) 15/05/01 08:30:33 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:838 15/05/01 08:30:33 INFO DAGScheduler: Submitting 1 missing tasks from Stage 1 (MappedRDD[7] at mapToPair at JavaWordCount.java:56) 15/05/01 08:30:33 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 15/05/01 08:30:33 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 15/05/01 08:30:33 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1115 bytes) 15/05/01 08:30:33 INFO Executor: Running task 0.0 in stage 1.0 (TID 1) 15/05/01 08:30:33 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 15/05/01 08:30:33 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 10 ms 15/05/01 08:30:34 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1000 bytes result sent to driver 15/05/01 08:30:34 INFO DAGScheduler: Stage 1 (mapToPair at JavaWordCount.java:56) finished in 0.155 s 15/05/01 08:30:34 INFO DAGScheduler: looking for newly runnable stages 15/05/01 08:30:34 INFO DAGScheduler: running: Set() 15/05/01 08:30:34 INFO DAGScheduler: waiting: Set(Stage 2) 15/05/01 08:30:34 INFO DAGScheduler: failed: Set() 15/05/01 08:30:34 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 154 ms on localhost (1/1) 15/05/01 08:30:34 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 15/05/01 08:30:34 INFO DAGScheduler: Missing parents for Stage 2: List() 15/05/01 08:30:34 INFO DAGScheduler: Submitting Stage 2 (ShuffledRDD[8] at reduceByKey at JavaWordCount.java:56), which is now runnable 15/05/01 08:30:34 INFO MemoryStore: ensureFreeSpace(2240) called with curMem=293417, maxMem=280248975 15/05/01 08:30:34 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 2.2 KB, free 267.0 MB) 15/05/01 08:30:34 INFO MemoryStore: ensureFreeSpace(1412) called with curMem=295657, maxMem=280248975 15/05/01 08:30:34 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 1412.0 B, free 267.0 MB) 15/05/01 08:30:34 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on localhost:37295 (size: 1412.0 B, free: 267.2 MB) 15/05/01 08:30:34 INFO BlockManagerMaster: Updated info of block broadcast_3_piece0 15/05/01 08:30:34 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:838 15/05/01 08:30:34 INFO DAGScheduler: Submitting 1 missing tasks from Stage 2 (ShuffledRDD[8] at reduceByKey at JavaWordCount.java:56) 15/05/01 08:30:34 INFO TaskSchedulerImpl: Adding task set 2.0 with 1 tasks 15/05/01 08:30:34 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 2, localhost, PROCESS_LOCAL, 1126 bytes) 15/05/01 08:30:34 INFO Executor: Running task 0.0 in stage 2.0 (TID 2) 15/05/01 08:30:34 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 15/05/01 08:30:34 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms 15/05/01 08:30:34 INFO Executor: Finished task 0.0 in stage 2.0 (TID 2). 1679 bytes result sent to driver 15/05/01 08:30:34 INFO DAGScheduler: Stage 2 (collect at JavaWordCount.java:83) finished in 0.033 s 15/05/01 08:30:34 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 2) in 12 ms on localhost (1/1) 15/05/01 08:30:34 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool 15/05/01 08:30:34 INFO DAGScheduler: Job 0 finished: collect at JavaWordCount.java:83, took 1.141125 s [(T,1), (w,5), (s,8), (d,9), (e,25), (p,1), (L,1), (B,1), (a,19), (t,11), (i,9), (;,1), (y,4), (u,6), (.,2), (h,10), (k,1), (b,3), (A,2), (O,1), (n,16), (o,10), (f,5), (I,2), (-,2), (v,5), (H,1), (,,2), (l,10), (g,3), (r,8), (m,8), (c,2)] [cloudera@quickstart JavaWordCount]
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization