Apache Hadoop : Creating Wordcount Maven Project with Eclipse - 2016
bogotobogo.com site search:
note
In this chapter, we'll continue to create a Wordcount project with Eclipse for Hadoop using Maven.
Here are my other tutorials related to "Word Count":
- Apache Hadoop Tutorial I with CDH - Overview
- Apache Hadoop Tutorial II with CDH - MapReduce Word Count
- Apache Hadoop Tutorial III with CDH - MapReduce Word Count 2
- Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 1
- Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 2
- Apache Hadoop : Creating Card Java Project with Eclipse using Cloudera VM UnoExample for CDH5 - local run
We're on Cloudera VM for CHD5.3.
Our java files
Here are the java files for our Word Count Maven project.
WordCount.jave:
package com.bogotobogo.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordCount extends Configured implements Tool{
public static void main(String[] args) throws Exception{
int exitCode = ToolRunner.run(new WordCount(), args);
System.exit(exitCode);
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = new org.apache.hadoop.mapreduce.Job();
job.setJarByClass(WordCount.class);
job.setJobName("WordCounter");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
int returnValue = job.waitForCompletion(true) ? 0:1;
System.out.println("job.isSuccessful " + job.isSuccessful());
return returnValue;
}
}
WordCountMapper.jave:
package com.bogotobogo.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer st = new StringTokenizer(line," ");
while(st.hasMoreTokens()){
word.set(st.nextToken());
context.write(word,one);
}
}
}
WordCountReducer.jave:
package com.bogotobogo.hadoop;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
Iterator<IntWritable> valuesIt = values.iterator();
while(valuesIt.hasNext()){
sum = sum + valuesIt.next().get();
}
context.write(key, new IntWritable(sum));
}
}
pom.xml
Here is our pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bogotobogo.hadoop</groupId>
<artifactId>wordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>wordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>0.20.2</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
</project>
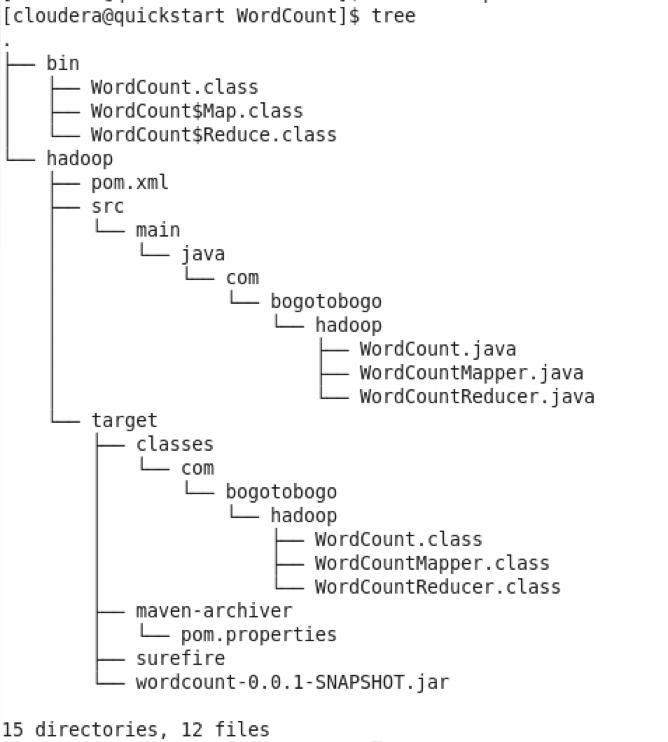
Results
Here is the results from our Maven project:
[cloudera@quickstart workspace]$ pwd /home/cloudera/workspace [cloudera@quickstart workspace]$ cd WordCount/ [cloudera@quickstart WordCount]$ ls bin hadoop
Input file
Here is our input:
[cloudera@quickstart input]$ hadoop fs -cat input/wordcount.txt It was many and many a year ago, In a kingdom by the sea, That a maiden there lived whom you may know By the name of Annabel Lee; And this maiden she lived with no other thought Than to love and be loved by me. ...
run
Time to run MapReduce job:
[cloudera@quickstart WordCount]$ pwd /home/cloudera/workspace/WordCount [cloudera@quickstart WordCount]$ hadoop jar hadoop/target/wordcount-0.0.1-SNAPSHOT.jar com.bogotobogo.hadoop.WordCount input/wordcount.txt output 15/03/28 21:24:50 INFO client.RMProxy: Connecting to ResourceManager at quickstart.cloudera/127.0.0.1:8032 15/03/28 21:24:50 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 15/03/28 21:24:51 INFO input.FileInputFormat: Total input paths to process : 1 15/03/28 21:24:51 INFO mapreduce.JobSubmitter: number of splits:1 15/03/28 21:24:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1427472032267_0019 15/03/28 21:24:51 INFO impl.YarnClientImpl: Submitted application application_1427472032267_0019 15/03/28 21:24:51 INFO mapreduce.Job: The url to track the job: http://quickstart.cloudera:8088/proxy/application_1427472032267_0019/ 15/03/28 21:24:51 INFO mapreduce.Job: Running job: job_1427472032267_0019 15/03/28 21:25:05 INFO mapreduce.Job: Job job_1427472032267_0019 running in uber mode : false 15/03/28 21:25:05 INFO mapreduce.Job: map 0% reduce 0% 15/03/28 21:25:11 INFO mapreduce.Job: map 100% reduce 0% 15/03/28 21:25:22 INFO mapreduce.Job: map 100% reduce 100% 15/03/28 21:25:22 INFO mapreduce.Job: Job job_1427472032267_0019 completed successfully 15/03/28 21:25:22 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=1315 FILE: Number of bytes written=219803 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=1687 HDFS: Number of bytes written=1113 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=4005 Total time spent by all reduces in occupied slots (ms)=4354 Total time spent by all map tasks (ms)=4005 Total time spent by all reduce tasks (ms)=4354 Total vcore-seconds taken by all map tasks=4005 Total vcore-seconds taken by all reduce tasks=4354 Total megabyte-seconds taken by all map tasks=4101120 Total megabyte-seconds taken by all reduce tasks=4458496 Map-Reduce Framework Map input records=46 Map output records=298 Map output bytes=2678 Map output materialized bytes=1311 Input split bytes=130 Combine input records=0 Combine output records=0 Reduce input groups=148 Reduce shuffle bytes=1311 Reduce input records=298 Reduce output records=148 Spilled Records=596 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=108 CPU time spent (ms)=640 Physical memory (bytes) snapshot=396996608 Virtual memory (bytes) snapshot=1717637120 Total committed heap usage (bytes)=303366144 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1557 File Output Format Counters Bytes Written=1113 job.isSuccessful true
output
Here is our output from the MR run:
[cloudera@quickstart WordCount]$ hadoop fs -ls output Found 2 items -rw-r--r-- 1 cloudera cloudera 0 2015-03-28 21:25 output/_SUCCESS -rw-r--r-- 1 cloudera cloudera 1113 2015-03-28 21:25 output/part-r-00000 [cloudera@quickstart WordCount]$ [cloudera@quickstart WordCount]$ hadoop fs -cat output/part-r-00000 (as 1 A 1 And 6 Annabel 7 But 2 By 1 Can 1 Chilling 1 ... wiser 1 with 2 without 1 year 1 you 1 [cloudera@quickstart WordCount]$
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization