Apache Hadoop (CDH 5) Flume with VirtualBox : syslog example via NettyAvroRpcClient
- Macbook Pro 16GB OSx 10.9.5
- java version "1.8.0_05"
- cloudera-quickstart-vm-5.3.0-virtualbox
- Virtual Box 4.3.24
In this tutorial, we'll recode syslog from the local machine to HDFS using flume. Two files are needed:
- target-agent.conf - the target flume agent that writes the data to HDFS (Cloudera QuickVM)
- source-agent.conf - the source flume agent that captures the syslog data (Mac Host)
We need to make local log directory as a root to echo the sys log:
$ sudo mkdir /var/log/flume-hdfs $ sudo chown hdfs:hadoop /var/log/flume-hdfs
Then, as hdfs user, we want to make a flume data directory in HDFS:
$ sudo su hdfs bash-4.1$ hdfs dfs -mkdir /user/hdfs/flume-channel/ $ hadoop fs -chmod -R 777 /user/hdfs/flume-channel
Apache Flume is a continuous data ingestion system. It can efficiently collect, aggregate, and move large amounts of log data. It uses a simple extensible data model that allows for online analytic application.
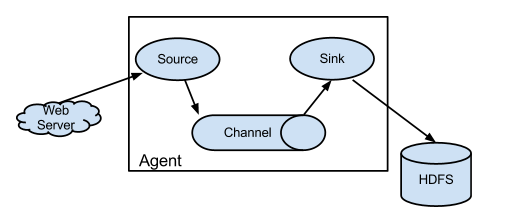
Picture source: https://flume.apache.org/.
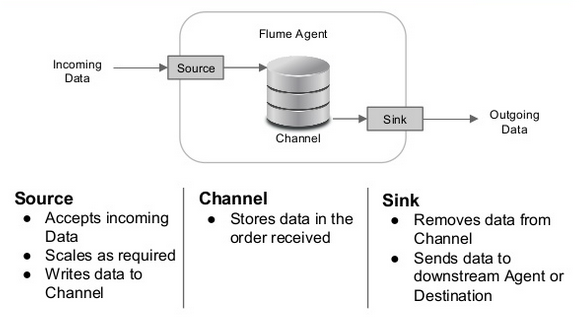
Picture source: Apache Flume.
Flume was originally designed to be a log aggregation system by Cloudera engineers, and evolved to handle any type of streaming event data.
"A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop)."
"A Flume source consumes events delivered to it by an external source like a web server. The external source sends events to Flume in a format that is recognized by the target Flume source. For example, an Avro Flume source can be used to receive Avro events from Avro clients or other Flume agents in the flow that send events from an Avro sink. A similar flow can be defined using a Thrift Flume Source to receive events from a Thrift Sink or a Flume Thrift Rpc Client or Thrift clients written in any language generated from the Flume thrift protocol.When a Flume source receives an event, it stores it into one or more channels. The channel is a passive store that keeps the event until it's consumed by a Flume sink. The file channel is one example - it is backed by the local filesystem. The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or forwards it to the Flume source of the next Flume agent (next hop) in the flow. The source and sink within the given agent run asynchronously with the events staged in the channel."
https://flume.apache.org/FlumeUserGuide.html.
Avro is a remote procedure call(RPC) and data serialization framework developed within Apache's Hadoop project. It uses JSON for defining data types and protocols, and serializes data in a compact binary format. Its primary use is in Apache Hadoop, where it can provide both a serialization format for persistent data, and a wire format for communication between Hadoop nodes, and from client programs to the Hadoop services.
It is similar to Thrift, but does not require running a code-generation program when a schema changes (unless desired for statically-typed languages).
From wiki.
My example consists of bringing a system.log from local Mac to HDFS via Cloudera QuickStart VM with Flume NG as a service of Cloudera Manager.
We will configure a collector listening for incoming flume events.
Here is the config (target-agent.conf):
## Sources ##
## Accept Avro data In from the Edge Agents
# http://flume.apache.org/FlumeUserGuide.html#avro-source
collector.sources = AvroIn
collector.sources.AvroIn.type = avro
collector.sources.AvroIn.bind = 0.0.0.0
collector.sources.AvroIn.port = 4545
collector.sources.AvroIn.channels = mc1 mc2
## Channels ##
## Source writes to 2 channels, one for each sink (Fan Out)
collector.channels = mc1 mc2
# http://flume.apache.org/FlumeUserGuide.html#memory-channel
collector.channels.mc1.type = memory
collector.channels.mc1.capacity = 100
collector.channels.mc2.type = memory
collector.channels.mc2.capacity = 100
## Sinks ##
collector.sinks = LocalOut HadoopOut
## Write to HDFS
# http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
collector.sinks.HadoopOut.type = hdfs
collector.sinks.HadoopOut.channel = mc2
#collector.sinks.HadoopOut.hdfs.path = /user/hdfs/flume-channel/%{log_type}/%{host}/%y%m%d
collector.sinks.HadoopOut.hdfs.path = /user/hdfs/flume-channel/%{log_type}/%y%m%d
collector.sinks.HadoopOut.hdfs.fileType = DataStream
collector.sinks.HadoopOut.hdfs.writeFormat = Text
collector.sinks.HadoopOut.hdfs.rollSize = 0
collector.sinks.HadoopOut.hdfs.rollCount = 10000
collector.sinks.HadoopOut.hdfs.rollInterval = 600
## Write copy to Local Filesystem (Debugging)
# If you want to use this sink, you must replace
# sinks with `collector.sinks = LocalOut HadoopOut`
# http://flume.apache.org/FlumeUserGuide.html#file-roll-sink
collector.sinks.LocalOut.type = file_roll
collector.sinks.LocalOut.sink.directory = /var/log/flume-hdfs
collector.sinks.LocalOut.sink.rollInterval = 0
collector.sinks.LocalOut.channel = mc1
$ sudo flume-ng agent -c conf -f target-agent.conf -n collector
[cloudera@quickstart Flume]$ sudo flume-ng agent -c conf -f target-agent.conf -n collector
Info: Including Hadoop libraries found via (/usr/bin/hadoop) for HDFS access
Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-log4j12.jar from classpath
Info: Including HBASE libraries found via (/usr/bin/hbase) for HBASE access
Info: Excluding /usr/lib/hbase/bin/../lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/lib/hbase/bin/../lib/slf4j-log4j12.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-log4j12.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/lib/hadoop/lib/slf4j-log4j12.jar from classpath
Info: Excluding /usr/lib/zookeeper/lib/slf4j-api-1.7.5.jar from classpath
Info: Excluding /usr/lib/zookeeper/lib/slf4j-log4j12-1.7.5.jar from classpath
Info: Excluding /usr/lib/zookeeper/lib/slf4j-log4j12.jar from classpath
...
15/04/05 12:51:53 INFO node.PollingPropertiesFileConfigurationProvider: Configuration provider starting
15/04/05 12:51:53 INFO node.PollingPropertiesFileConfigurationProvider: Reloading configuration file:target-agent.conf
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:LocalOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:LocalOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:LocalOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:LocalOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Added sinks: LocalOut HadoopOut Agent: collector
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Processing:HadoopOut
15/04/05 12:51:53 INFO conf.FlumeConfiguration: Post-validation flume configuration contains configuration for agents: [collector]
15/04/05 12:51:53 INFO node.AbstractConfigurationProvider: Creating channels
15/04/05 12:51:53 INFO channel.DefaultChannelFactory: Creating instance of channel mc2 type memory
15/04/05 12:51:53 INFO node.AbstractConfigurationProvider: Created channel mc2
15/04/05 12:51:53 INFO channel.DefaultChannelFactory: Creating instance of channel mc1 type memory
15/04/05 12:51:53 INFO node.AbstractConfigurationProvider: Created channel mc1
15/04/05 12:51:53 INFO source.DefaultSourceFactory: Creating instance of source AvroIn, type avro
15/04/05 12:51:53 INFO sink.DefaultSinkFactory: Creating instance of sink: LocalOut, type: file_roll
15/04/05 12:51:53 INFO sink.DefaultSinkFactory: Creating instance of sink: HadoopOut, type: hdfs
15/04/05 12:51:53 INFO hdfs.HDFSEventSink: Hadoop Security enabled: false
15/04/05 12:51:53 INFO node.AbstractConfigurationProvider: Channel mc2 connected to [AvroIn, HadoopOut]
15/04/05 12:51:53 INFO node.AbstractConfigurationProvider: Channel mc1 connected to [AvroIn, LocalOut]
15/04/05 12:51:53 INFO node.Application: Starting new configuration:{ sourceRunners:{AvroIn=EventDrivenSourceRunner: { source:Avro source AvroIn: { bindAddress: 0.0.0.0, port: 4545 } }} sinkRunners:{LocalOut=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@61e34259 counterGroup:{ name:null counters:{} } }, HadoopOut=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@f191344 counterGroup:{ name:null counters:{} } }} channels:{mc2=org.apache.flume.channel.MemoryChannel{name: mc2}, mc1=org.apache.flume.channel.MemoryChannel{name: mc1}} }
15/04/05 12:51:53 INFO node.Application: Starting Channel mc2
15/04/05 12:51:53 INFO node.Application: Starting Channel mc1
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: mc1: Successfully registered new MBean.
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: mc1 started
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: mc2: Successfully registered new MBean.
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: mc2 started
15/04/05 12:51:53 INFO node.Application: Starting Sink LocalOut
15/04/05 12:51:53 INFO sink.RollingFileSink: Starting org.apache.flume.sink.RollingFileSink{name:LocalOut, channel:mc1}...
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SINK, name: LocalOut: Successfully registered new MBean.
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: LocalOut started
15/04/05 12:51:53 INFO sink.RollingFileSink: RollInterval is not valid, file rolling will not happen.
15/04/05 12:51:53 INFO sink.RollingFileSink: RollingFileSink LocalOut started.
15/04/05 12:51:53 INFO node.Application: Starting Sink HadoopOut
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SINK, name: HadoopOut: Successfully registered new MBean.
15/04/05 12:51:53 INFO instrumentation.MonitoredCounterGroup: Component type: SINK, name: HadoopOut started
15/04/05 12:51:53 INFO node.Application: Starting Source AvroIn
15/04/05 12:51:53 INFO source.AvroSource: Starting Avro source AvroIn: { bindAddress: 0.0.0.0, port: 4545 }...
15/04/05 12:51:54 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SOURCE, name: AvroIn: Successfully registered new MBean.
15/04/05 12:51:54 INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: AvroIn started
15/04/05 12:51:54 INFO source.AvroSource: Avro source AvroIn started.
15/04/05 12:51:56 INFO ipc.NettyServer: [id: 0xea3b33d8, /192.168.56.10:53866 => /192.168.56.101:4545] OPEN
15/04/05 12:51:56 INFO ipc.NettyServer: [id: 0xea3b33d8, /192.168.56.10:53866 => /192.168.56.101:4545] BOUND: /192.168.56.101:4545
15/04/05 12:51:56 INFO ipc.NettyServer: [id: 0xea3b33d8, /192.168.56.10:53866 => /192.168.56.101:4545] CONNECTED: /192.168.56.10:53866
Now we have the collector listening for incoming flume events (waiting for an input).
Now, we want to move over to the HOST environment (mac).
Download the tarball matching the cloudera VM version (1.5.0 from http://archive.apache.org/dist/flume/)
Install the tarball:
$ sudo mv apache-flume-1.3.0-bin /usr/local/ $ sudo ln -s /usr/local/apache-flume-1.3.0-bin /usr/local/flume
Here is our conf for source Flume agent (source-agent.conf):
# The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called 'agent' # For details on how this is used check out geovanie.me, the article on FLume. ##### # SOURCE ##### agent.sources = tail-source agent.sources.tail-source.type = exec agent.sources.tail-source.command = tail -F /var/log/system.log agent.sources.tail-source.batchSize = 1 agent.sources.tail-source.channels = memory-channel agent.sources.tail-source.interceptors = itime ihost itype # http://flume.apache.org/FlumeUserGuide.html#timestamp-interceptor agent.sources.tail-source.interceptors.itime.type = timestamp # http://flume.apache.org/FlumeUserGuide.html#host-interceptor agent.sources.tail-source.interceptors.ihost.type = host agent.sources.tail-source.interceptors.ihost.useIP = false agent.sources.tail-source.interceptors.ihost.hostHeader = host # http://flume.apache.org/FlumeUserGuide.html#static-interceptor agent.sources.tail-source.interceptors.itype.type = static agent.sources.tail-source.interceptors.itype.key = log_type agent.sources.tail-source.interceptors.itype.value = my_mac_syslog #### # CHANNEL #### agent.channels = memory-channel agent.channels.memory-channel.type = memory agent.channels.memory-channel.capacity = 100 #### # SINK #### agent.sinks = avro-sink log-sink agent.sinks.avro-sink.type = avro agent.sinks.avro-sink.channel = memory-channel agent.sinks.avro-sink.hostname = 192.168.56.101 agent.sinks.avro-sink.port = 4545 agent.sinks.log-sink.channel = memory-channel agent.sinks.log-sink.type = logger
On our host OS (mac):
$ sudo /usr/local/flume/bin/flume-ng agent -c /usr/local/flume/conf -f /usr/local/flume/conf/source-agent.conf -Dflume.root.logger=DEBUG,console -n agent
...
2015-04-05 13:33:50,862 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{log_type=my_mac_syslog, host=ip-192-168-1-5.us-west-1.compute.internal, timestamp=1428266030862} body: 41 70 72 20 20 35 20 31 33 3A 33 33 3A 35 30 20 Apr 5 13:33:50 }
2015-04-05 13:33:59,866 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{log_type=my_mac_syslog, host=ip-192-168-1-5.us-west-1.compute.internal, timestamp=1428266038517} body: 41 70 72 20 20 35 20 31 33 3A 33 33 3A 35 38 20 Apr 5 13:33:58 }
...
Once the source agent is running, we can see something is being written to our hdfs:
15/04/05 13:23:56 INFO ipc.NettyServer: [id: 0x4fb171e9, /192.168.56.10:54078 => /192.168.56.101:4545] OPEN 15/04/05 13:23:56 INFO ipc.NettyServer: [id: 0x4fb171e9, /192.168.56.10:54078 => /192.168.56.101:4545] BOUND: /192.168.56.101:4545 15/04/05 13:23:56 INFO ipc.NettyServer: [id: 0x4fb171e9, /192.168.56.10:54078 => /192.168.56.101:4545] CONNECTED: /192.168.56.10:54078 15/04/05 13:25:14 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false 15/04/05 13:25:14 INFO hdfs.BucketWriter: Creating /user/hdfs/flume-channel/my_mac_syslog/150405/FlumeData.1428265514297.tmp
[cloudera@quickstart flume-hdfs]$ tail -f /var/log/flume-hdfs/1428265419438-1 Apr 5 13:29:39 ip-192-168-1-5.us-west-1.compute.internal iTerm[31289]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:30:13 ip-192-168-1-5.us-west-1.compute.internal Terminal[282]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:30:18 ip-192-168-1-5.us-west-1.compute.internal login[89972]: DEAD_PROCESS: 89972 ttys002 Apr 5 13:32:24 ip-192-168-1-5.us-west-1.compute.internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:16 ip-192-168-1-5.us-west-1.compute.internal Mail[29747]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:25 ip-192-168-1-5.us-west-1.compute.internal Skype[71643]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:29 ip-192-168-1-5.us-west-1.compute.internal SourceTree[287]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:35:00 ip-192-168-1-5.us-west-1.compute.internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:35:30 --- last message repeated 1 time --- Apr 5 13:35:34 ip-192-168-1-5.us-west-1.compute.internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150
[cloudera@quickstart log]$ hadoop fs -ls /user/hdfs/flume-channel/my_mac_syslog/150405 Found 2 items -rw-r--r-- 1 root supergroup 1471 2015-04-05 13:35 /user/hdfs/flume-channel/my_mac_syslog/150405/FlumeData.1428265514297 -rw-r--r-- 1 root supergroup 178 2015-04-05 13:35 /user/hdfs/flume-channel/my_mac_syslog/150405/FlumeData.1428266137369.tmp [cloudera@quickstart log]$ hadoop fs -tail /user/hdfs/flume-channel/my_mac_syslog/150405/FlumeData.1428265514297 internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:29:39 ip-192-168-1-5.us-west-1.compute.internal iTerm[31289]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:30:13 ip-192-168-1-5.us-west-1.compute.internal Terminal[282]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:30:18 ip-192-168-1-5.us-west-1.compute.internal login[89972]: DEAD_PROCESS: 89972 ttys002 Apr 5 13:32:24 ip-192-168-1-5.us-west-1.compute.internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:16 ip-192-168-1-5.us-west-1.compute.internal Mail[29747]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:25 ip-192-168-1-5.us-west-1.compute.internal Skype[71643]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:33:29 ip-192-168-1-5.us-west-1.compute.internal SourceTree[287]: CGSCopyDisplayUUID: Invalid display 0x2b101150 Apr 5 13:35:00 ip-192-168-1-5.us-west-1.compute.internal Google Chrome[284]: CGSCopyDisplayUUID: Invalid display 0x2b101150
- https://flume.apache.org/FlumeUserGuide.html
- https://flume.apache.org/FlumeDeveloperGuide.html#
- CDH5 and Flume on Mac
- Hadoop fundamentals Demostrate apache flume example part2
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization