Zookeeper & Kafka Install : A single node and a single broker cluster - 2016
In the previous chapter (Zookeeper & Kafka - Install), we installed Kafka and Zookeeper.
In this chapter, we want to setup a single-node single-broker Kafka as shown in the picture below:
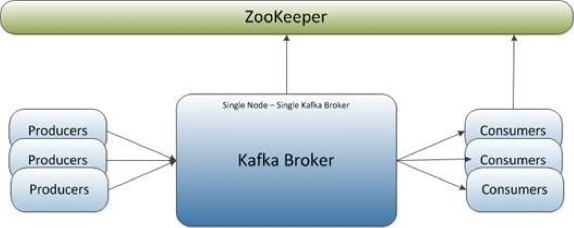
Picture source: Learning Apache Kafka 2nd ed. 2015
In previous chapter, we ran ZooKeeper package that's available in Ubuntu's default repositories as daemon (zookeeperd).
Let's stop the ZooKeeper daemon if it's running:
$ sudo /usr/share/zookeeper/bin/zkServer.sh stop
To launch a single local Zookeeper, we'll use the default configuration (~/kafka/config/zookeeper.properties) that Kafka provides instead of /etc/zookeeper/conf/zoo.cfg.
$ ls ~/kafka/config connect-console-sink.properties connect-file-source.properties log4j.properties zookeeper.properties connect-console-source.properties connect-log4j.properties producer.properties connect-distributed.properties connect-standalone.properties server.properties connect-file-sink.properties consumer.properties tools-log4j.properties
Let's start the local Zookeeper instance:
$ ~/kafka/bin/zookeeper-server-start.sh ~/kafka/config/zookeeper.properties
Kafka provides us with the required property files which defining minimal properties required for a single broker-single node cluster. For example, ~/kafka/config/zookeeper.properties has the following lines:
# the directory where the snapshot is stored. dataDir=/tmp/zookeeper # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=0
The Zookeeper, by default, will listen on *:2181/tcp.
From ZooKeeper Overview.
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical name space of data registers (we call these registers znodes), much like a file system.
Unlike normal file systems, ZooKeeper provides its clients with high throughput, low latency, highly available, strictly ordered access to the znodes.
The performance aspects of ZooKeeper allows it to be used in large distributed systems.
The reliability aspects prevent it from becoming the single point of failure in big systems.
Its strict ordering allows sophisticated synchronization primitives to be implemented at the client.
The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/).
Every znode in ZooKeeper's name space is identified by a path. And every znode has a parent whose path is a prefix of the znode with one less element; the exception to this rule is root (/) which has no parent. Also, exactly like standard file systems, a znode cannot be deleted if it has any children.
The main differences between ZooKeeper and standard file systems are that every znode can have data associated with it (every file can also be a directory and vice-versa) and znodes are limited to the amount of data that they can have.
ZooKeeper was designed to store coordination data: status information, configuration, location information, etc. This kind of meta-information is usually measured in kilobytes, if not bytes.
ZooKeeper has a built-in sanity check of 1M, to prevent it from being used as a large data store, but in general it is used to store much smaller pieces of data.
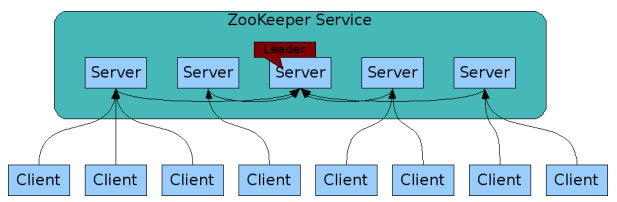
The service itself is replicated over a set of machines that comprise the service. These machines maintain an in-memory image of the data tree along with a transaction logs and snapshots in a persistent store. Because the data is kept in-memory, ZooKeeper is able to get very high throughput and low latency numbers. The downside to an in memory database is that the size of the database that ZooKeeper can manage is limited by memory. This limitation is further reason to keep the amount of data stored in znodes small.
The servers that make up the ZooKeeper service must all know about each other. As long as a majority of the servers are available, the ZooKeeper service will be available. Clients must also know the list of servers. The clients create a handle to the ZooKeeper service using this list of servers.
Clients only connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server. When a client first connects to the ZooKeeper service, the first ZooKeeper server will setup a session for the client. If the client needs to connect to another server, this session will get reestablished with the new server.
Read requests sent by a ZooKeeper client are processed locally at the ZooKeeper server to which the client is connected. If the read request registers a watch on a znode, that watch is also tracked locally at the ZooKeeper server. Write requests are forwarded to other ZooKeeper servers and go through consensus before a response is generated. Sync requests are also forwarded to another server, but does not actually go through consensus. Thus, the throughput of read requests scales with the number of servers and the throughput of write requests decreases with the number of servers.
Order is very important to ZooKeeper. (They tend to be a bit obsessive compulsive.) All updates are totally ordered. ZooKeeper actually stamps each update with a number that reflects this order. We call this number the zxid (ZooKeeper Transaction Id). Each update will have a unique zxid. Reads (and watches) are ordered with respect to updates. Read responses will be stamped with the last zxid processed by the server that services the read.
Let's check Kafka properties (~/kafka/config/server.properties):
############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=0 # Switch to enable topic deletion or not, default value is false delete.topic.enable=true ############################# Socket Server Settings ############################# # The port the socket server listens on port=9092 ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=localhost:2181
Topics are logical grouping of messages. They provide a way to isolate data from other consumers if necessary.
Kafka provides a command line utility named kafka-topics.sh to create topics on the server:
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 \ --replication-factor 1 --partitions 1 --topic Hello-Kafka Created topic "Hello-Kafka".
The more partitions we have, the more throughput we get when consuming data. From the producer standpoint, Kafka provides us an option for controlling which data ends up in which partition.
The partition count controls how many logs the topic will be sharded into. There are several impacts of the partition count. First each partition must fit entirely on a single server. So if you have 20 partitions the full data set (and read and write load) will be handled by no more than 20 servers (no counting replicas). Finally the partition count impacts the maximum parallelism of your consumers. - Kafka's documentation
We just created a topic named Hello-Kafka with a single partition and one replica factor.
Once the topic has been created, we can get the notification in Kafka broker terminal and the log for the created topic specified in "/tmp/kafka-logs/" directory:
$ ls -la /tmp/kafka-logs total 52 drwxrwxr-x 3 k k 4096 Mar 10 17:57 . drwxrwxrwt 40 root root 24576 Mar 10 17:56 .. -rw-rw-r-- 1 k k 4 Mar 10 13:09 cleaner-offset-checkpoint drwxrwxr-x 2 k k 4096 Mar 10 17:44 Hello-Kafka-0 -rw-rw-r-- 1 k k 0 Mar 9 21:51 .lock -rw-rw-r-- 1 k k 54 Mar 9 21:51 meta.properties -rw-rw-r-- 1 k k 32 Mar 10 17:56 recovery-point-offset-checkpoint -rw-rw-r-- 1 k k 20 Mar 10 17:57 replication-offset-checkpoint
To list of topics in Kafka server, we can use "--list" flag:
$ bin/kafka-topics.sh --list --zookeeper localhost:2181 Hello-Kafka
To publish messages, we need to create a Kafka producer from the command line using the bin/kafka-console-producer.sh script. It requires the Kafka server's hostname and port, along with a topic name as its arguments.
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka
The broker-list specified of brokers that we want to send the messages to. In our case, we have only one broker. Note that we specified he port 9090 to which our broker is listening.
The producer will wait on input from stdin and publishes to the Kafka cluster. By default, every new line is published as a new message.
Let's type a few lines of messages in the terminal as shown below:
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-Kafka The first message The second message
The default consumer properties are specified in config/consumer.properties. Open a new terminal and type the following to consume messages:
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic Hello-Kafka --from-beginning The first message The second message
Now we can see the messages in the consumer's terminal that we entered from the producer's terminal.
Deletion of a topic has been supported since 0.8.2.x version. We have to enable topic deletion (setting delete.topic.enable to true) on all brokers first:
$ ~/kafka/bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic MyTopic
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization