Apache Drill - Query HBase
HBase is a non-relational (NoSQL) database that runs on top of HDFS, and it provides real-time random read/write access to our datasets in Hadoop.
HBase scales linearly to handle huge data sets with huge number of rows and columns, and it easily combines data sources that use a wide variety of different structures and schemas.
HBase is natively integrated with Hadoop and works seamlessly alongside other data access engines through YARN.
It was created for hosting very large tables, making it a great choice to store multi-structured or sparse data. Users can query HBase for a particular point in time, making “flashback” queries possible.
HBase scales linearly by requiring all tables to have a primary key. The key space is divided into sequential blocks that are then allotted to a region.
RegionServers own one or more regions, so the load is spread uniformly across the cluster. If the keys within a region are frequently accessed, HBase can further subdivide the region by splitting it automatically, so that manual data sharding is not necessary.
ZooKeeper and HMaster servers make information about the cluster topology available to clients. Clients connect to these and download a list of RegionServers, the regions contained within those RegionServers and the key ranges hosted by the regions. Clients know exactly where any piece of data is in HBase and can contact the RegionServer directly without any need for a central coordinator.
RegionServers include a memstore to cache frequently accessed rows in memory. Optionally, users can store rows off-heap, caching gigabytes of data while minimizing pauses for garbage collection.
From http://hortonworks.com/apache/hbase/.
At the time of writing this tutorial, Drill 1.8 is the most recent version. However, 1.8 (http://www-us.apache.org/dist/drill/drill-1.8.0/apache-drill-1.8.0.tar.gz) & 1.7 (http://archive.apache.org/dist/drill/drill-1.6.0/apache-drill-1.6.0.tar.gz) seem to have some issues regarding HBase "Select". So, I had to use earlier release (http://archive.apache.org/dist/drill/drill-1.6.0/apache-drill-1.6.0.tar.gz) to query HBase data.
For example, with 1.7 & 1.8, error occurred during the Foreman phase of the query.:
0: jdbc:drill:zk=local> ALTER SESSION SET `exec.errors.verbose` = true; +-------+-------------------------------+ | ok | summary | +-------+-------------------------------+ | true | exec.errors.verbose updated. | +-------+-------------------------------+ 1 row selected (0.353 seconds) 0: jdbc:drill:zk=local> select * from hbase.customers; Error: SYSTEM ERROR: IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator [Error Id: d6488618-c553-478f-b922-55e1d269027e on laptop:31010] (org.apache.drill.exec.work.foreman.ForemanException) Unexpected exception during fragment initialization: Internal error: Error while applying rule DrillPushProjIntoScan, args [rel#1480:LogicalProject.NONE.ANY([]).[](input=rel#1479:Subset#0.ENUMERABLE.ANY([]).[],row_key=$0,iteminfo=$1,purchaseinfo=$2), rel#1470:EnumerableTableScan.ENUMERABLE.ANY([]).[](table=[hbase, purchases])] org.apache.drill.exec.work.foreman.Foreman.run():281 java.util.concurrent.ThreadPoolExecutor.runWorker():1142 java.util.concurrent.ThreadPoolExecutor$Worker.run():617 java.lang.Thread.run():745 Caused By (java.lang.AssertionError) Internal error: Error while applying rule DrillPushProjIntoScan, args [rel#1480:LogicalProject.NONE.ANY([]).[](input=rel#1479:Subset#0.ENUMERABLE.ANY([]).[],row_key=$0,iteminfo=$1,purchaseinfo=$2), rel#1470:EnumerableTableScan.ENUMERABLE.ANY([]).[](table=[hbase, purchases])] org.apache.calcite.util.Util.newInternal():792 org.apache.calcite.plan.volcano.VolcanoRuleCall.onMatch():251 org.apache.calcite.plan.volcano.VolcanoPlanner.findBestExp():808 org.apache.calcite.tools.Programs$RuleSetProgram.run():303 ...
There is a Drill trouble shooting document regarding the issue : Unexpected Exception during Fragment Initialization, but I could not get much help from the doc.
With Drill 1.6, however, everything seems working fine at least for querying HBase table, as we can see from the sections below.
To query an HBase data source using Drill, we need to configure the HBase storage plugin for our environment.
When connecting Drill to an HBase data source using the HBase storage plugin installed with Drill, we need to specify a ZooKeeper quorum. Drill supports HBase version 0.98.
To view or change the HBase storage plugin configuration, we want to use the Drill Web Console. In the Web Console, select the Storage tab, and then click the Update button for the hbase storage plugin configuration:
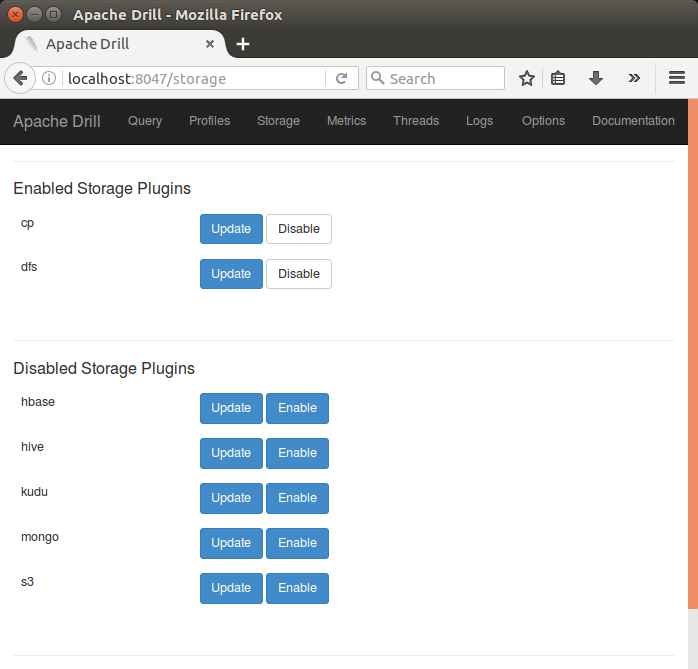
The following is the default HBase storage plugin, and we'll use it as it is:
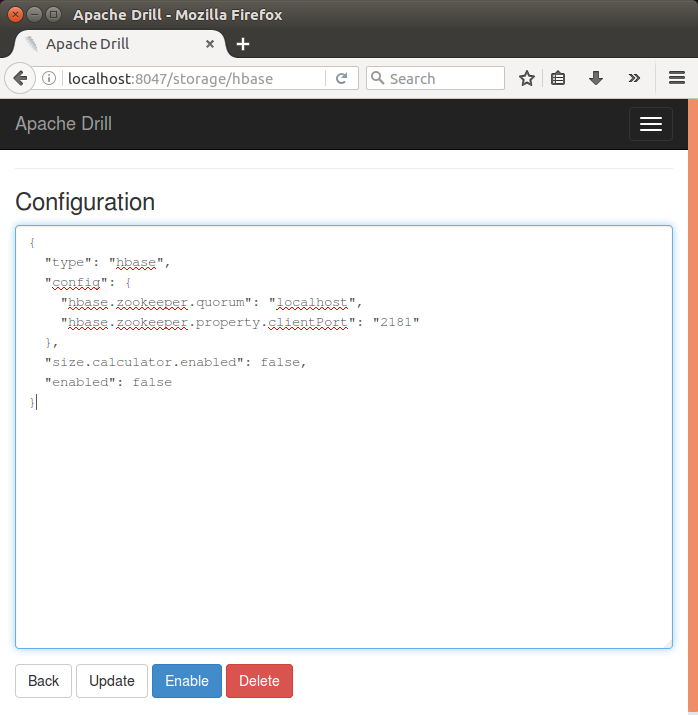
Click "Enable" and "Back", then we can see the HBase plugin has been enabled:
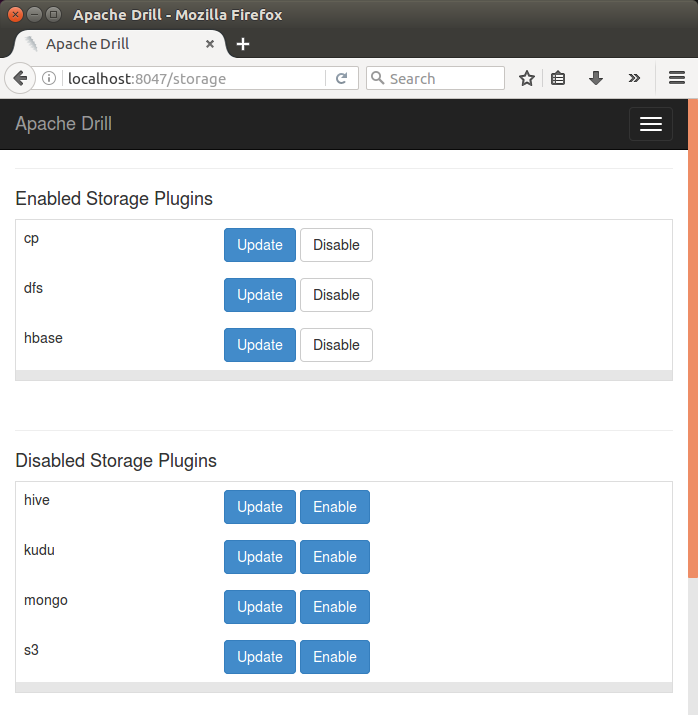
Before we store data to HDFS via HBase, we need to install them. In other words, the followings are should be running:
hduser@laptop:$ jps 6496 Main 3026 DataNode 2916 NameNode 3812 HRegionServer 6572 Jps 3694 HMaster 3231 SecondaryNameNode
Here are the links for the installing process:
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)HBase in Pseudo-Distributed mode
We'll create a table, customers, that we can query with Drill.
We're going to the CONVERT_TO and CONVERT_FROM functions to convert binary text to/from typed data. We'll also use the CAST function to convert the binary data to an INT. When converting an INT or BIGINT number, having a byte count in the destination/source that does not match the byte count of the number in the binary source/destination, we need to use CAST.
The syntax to create a table looks like this:
create '<table-name>','<column-family1>' ,'<column-family2>'
Let's create a HBase table by following steps below:
- Use the following commands to the HBase shell to create customers table in HBase:
hbase(main):001:0> create 'customers','account','address' 0 row(s) in 4.5380 seconds => Hbase::Table - customers
- We can check the list of tables we created:
hbase(main):002:0> list TABLE customers 1 row(s) in 0.0730 seconds => ["customers"]
- Now, it's time to populate the table using put command:
hbase(main):003:0> put 'customers','customer1','account:name','Trump' 0 row(s) in 0.1610 seconds hbase(main):004:0> put 'customers','customer1','address:street','123 Golden Gate Av' 0 row(s) in 0.0670 seconds hbase(main):005:0> put 'customers','customer1','address:zipcode','94511' 0 row(s) in 0.0460 seconds hbase(main):006:0> put 'customers','customer1','address:state','CA' 0 row(s) in 0.0790 seconds
- Let's check the contents:
hbase(main):008:0> get 'customers', 'customer1' COLUMN CELL account:name timestamp=1479935310671, value=Trump address:state timestamp=1479935348197, value=CA address:street timestamp=1479935324923, value=123 Golden Gate Av address:zipcode timestamp=1479935338251, value=94511 4 row(s) in 0.1140 seconds
Start Drill and follow the steps below to query the HBase tables we created.
- Drill shell:
root@laptop:/usr/local/apache-drill-1.6.0# bin/drill-embedded ... apache drill 1.6.0
- Issue !tables command to see the tables from Drill shell:
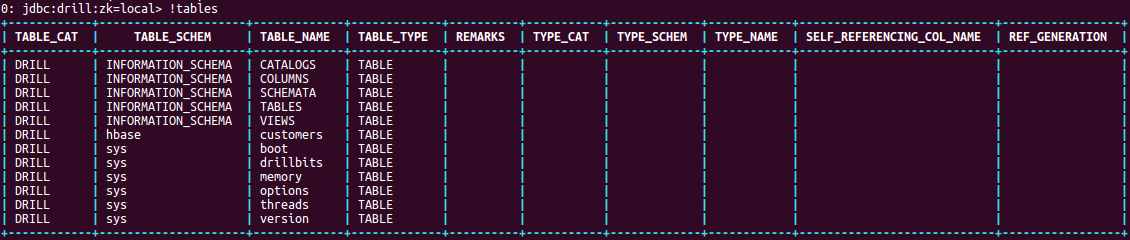
- Now, type use hbase to change the storage to HBase:
0: jdbc:drill:zk=local> use hbase; +-------+------------------------------------+ | ok | summary | +-------+------------------------------------+ | true | Default schema changed to [hbase] | +-------+------------------------------------+ 1 row selected (1.445 seconds)
- Now that the default storage has been changed to HBase, we can now perform Drill queries on HBase tables:
0: jdbc:drill:zk=local> show tables; +---------------+-------------+ | TABLE_SCHEMA | TABLE_NAME | +---------------+-------------+ | hbase | customers | +---------------+-------------+ 1 row selected (2.009 seconds)
- Let's see the contents of the table customers, using the command select * form customers:
0: jdbc:drill:zk=local> select * from customers; +---------------------+----------------------+----------------------------------------------------------------------------+ | row_key | account | address | +---------------------+----------------------+----------------------------------------------------------------------------+ | 637573746F6D657231 | {"name":"VHJ1bXA="} | {"state":"Q0E=","street":"MTIzIEdvbGRlbiBHYXRlIEF2","zipcode":"OTQ1MTE="} | +---------------------+----------------------+----------------------------------------------------------------------------+ 1 row selected (3.239 seconds) - As we can see that the output was not readable. Drill uses UTF8 text format but HBase stores its data in byte arrays. So, we need to add CONVERT_FROM statement to convert the output in readable format.
Let's write the query to convert the byte arrays to UTF8 format. The query should look like this:0: jdbc:drill:zk=local> SELECT CONVERT_FROM(row_key, 'UTF8') AS customerid, . . . . . . . . . . . > CONVERT_FROM(customers.account.name, 'UTF8') AS name, . . . . . . . . . . . > CONVERT_FROM(customers.address.state, 'UTF8') AS state, . . . . . . . . . . . > CONVERT_FROM(customers.address.street, 'UTF8') AS street, . . . . . . . . . . . > CONVERT_FROM(customers.address.zipcode, 'UTF8') AS zipcode . . . . . . . . . . . > FROM customers; +-------------+--------+--------+---------------------+----------+ | customerid | name | state | street | zipcode | +-------------+--------+--------+---------------------+----------+ | customer1 | Trump | CA | 123 Golden Gate Av | 94511 | +-------------+--------+--------+---------------------+----------+ 1 row selected (2.025 seconds)
Note that to access the data in an HBase table through a Drill query, we need to access it through the dot operator. So, the syntax should look like tablename.columnfamilyname.columnnname.
Big Data & Drill Tutorials
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization