AWS : Redshift data warehouse
Amazon.com chief technology officer Werner Vogels, in AWS Summit Amazon's AWS Summit in London, said Redshift data warehouse is the fastest-growing service in AWS's nine-year history.
Vogels said during his morning keynote, having the power to scale between one and thousands of nodes at their fingertips "really hit something that enterprise and business need at this moment", though he didn't provide by how much Redshift was growing.
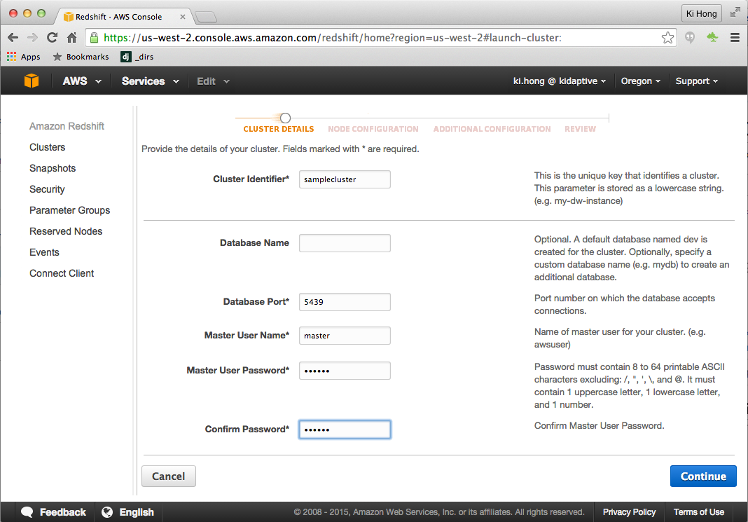
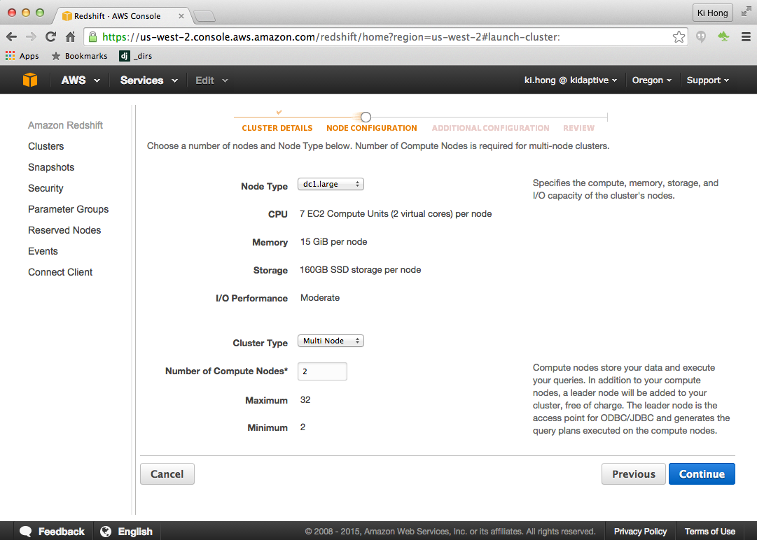
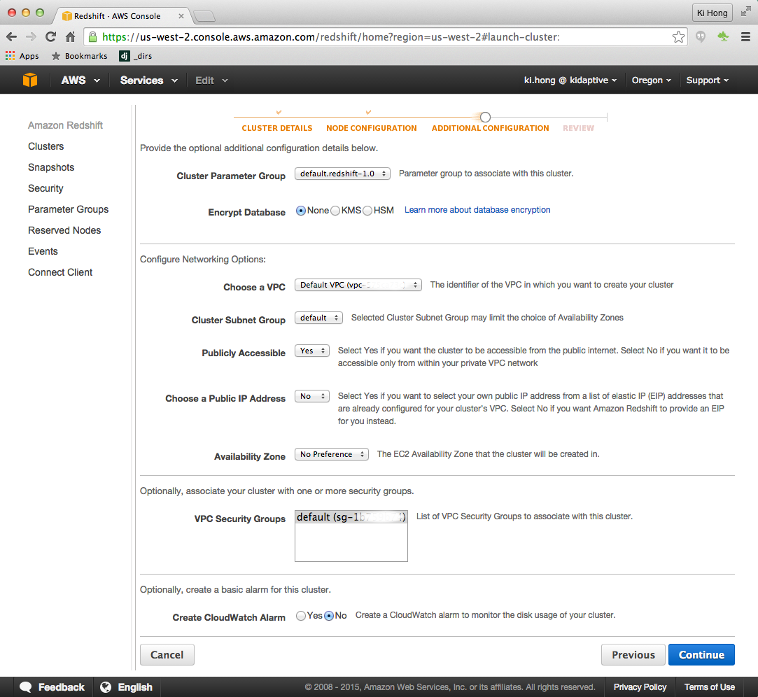
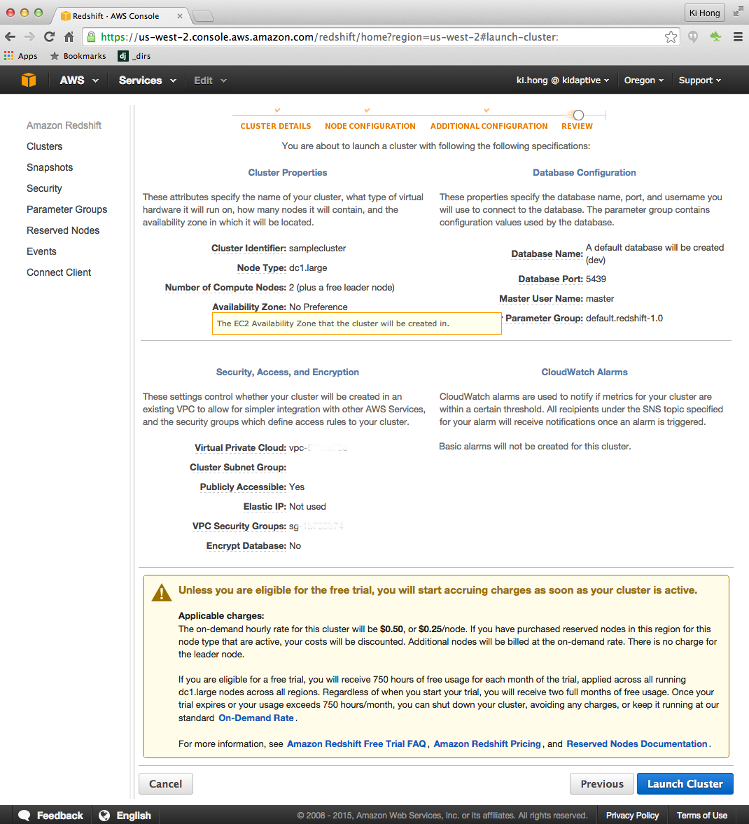
Amazon Redshift is a petabyte-scale data warehouse hosting service. It is part of the popular Amazon Web Services (AWS) cloud computing platform. Redshift is based on a massively parallel processing (MPP) architecture, and its columnar storage technology augments query performance by parallelizing queries across several nodes. For a minimal fee, Redshift will simplify our data warehouse needs by allowing us to set up, operate, and scale our cloud-based data warehouse using an intuitive and easy-to-use management console.
Redshift has gained a lot of popularity following its 2013 release. Compared with traditional data warehouses which require custom hardware and software that took too much maintenance and cost way too much money, Redshift broke this strict paradigm by moving the whole operation onto the cloud.
Redshift is a service that we must provision for ourselves: First, we have to decide which kind of server we want, and then we should turn it on. We'll get charged by the amount of hours the servers are kept alive.
On the other hand, with Google BigQuery we don't need to worry about servers or provisioning them. There are only 2 variables we get charged by: How much data we upload, and how much data our queries query. The service is always on.
So, I do not want to call one of them "better" than the other since they are just different, and it may depend on the needs.
Hive is an open source data warehousing framework built on top of Hadoop. It runs queries against a Hadoop cluster, which stores unstructured, distributed data. Hive was designed to analyze large sets of data, and is compatible with different file systems, primarily the Hadoop Distributed File System (HDFS).
Both Hive and Redshift are good solutions, the choice usually depends on a particular need. Redshift is the winner in terms of price and ease of use, but regarding the performance, Hive is the winner in the petabyte range of data.
Since Hadoop is geared toward extremely large datasets, Hive is a good choice if our data warehouse deals with massive amounts of data. Amazon Redshift, on the other hand, is the better choice for organizations with limited resources and lack of technical expertise. As far as performance is concerned, Redshift is the winner in the terabyte range, but above a certain level, we have no choice but to go with Hive on Hadoop.
AWS (Amazon Web Services)
- AWS : EKS (Elastic Container Service for Kubernetes)
- AWS : Creating a snapshot (cloning an image)
- AWS : Attaching Amazon EBS volume to an instance
- AWS : Adding swap space to an attached volume via mkswap and swapon
- AWS : Creating an EC2 instance and attaching Amazon EBS volume to the instance using Python boto module with User data
- AWS : Creating an instance to a new region by copying an AMI
- AWS : S3 (Simple Storage Service) 1
- AWS : S3 (Simple Storage Service) 2 - Creating and Deleting a Bucket
- AWS : S3 (Simple Storage Service) 3 - Bucket Versioning
- AWS : S3 (Simple Storage Service) 4 - Uploading a large file
- AWS : S3 (Simple Storage Service) 5 - Uploading folders/files recursively
- AWS : S3 (Simple Storage Service) 6 - Bucket Policy for File/Folder View/Download
- AWS : S3 (Simple Storage Service) 7 - How to Copy or Move Objects from one region to another
- AWS : S3 (Simple Storage Service) 8 - Archiving S3 Data to Glacier
- AWS : Creating a CloudFront distribution with an Amazon S3 origin
- AWS : Creating VPC with CloudFormation
- AWS : WAF (Web Application Firewall) with preconfigured CloudFormation template and Web ACL for CloudFront distribution
- AWS : CloudWatch & Logs with Lambda Function / S3
- AWS : Lambda Serverless Computing with EC2, CloudWatch Alarm, SNS
- AWS : Lambda and SNS - cross account
- AWS : CLI (Command Line Interface)
- AWS : CLI (ECS with ALB & autoscaling)
- AWS : ECS with cloudformation and json task definition
- AWS Application Load Balancer (ALB) and ECS with Flask app
- AWS : Load Balancing with HAProxy (High Availability Proxy)
- AWS : VirtualBox on EC2
- AWS : NTP setup on EC2
- AWS: jq with AWS
- AWS & OpenSSL : Creating / Installing a Server SSL Certificate
- AWS : OpenVPN Access Server 2 Install
- AWS : VPC (Virtual Private Cloud) 1 - netmask, subnets, default gateway, and CIDR
- AWS : VPC (Virtual Private Cloud) 2 - VPC Wizard
- AWS : VPC (Virtual Private Cloud) 3 - VPC Wizard with NAT
- DevOps / Sys Admin Q & A (VI) - AWS VPC setup (public/private subnets with NAT)
- AWS - OpenVPN Protocols : PPTP, L2TP/IPsec, and OpenVPN
- AWS : Autoscaling group (ASG)
- AWS : Setting up Autoscaling Alarms and Notifications via CLI and Cloudformation
- AWS : Adding a SSH User Account on Linux Instance
- AWS : Windows Servers - Remote Desktop Connections using RDP
- AWS : Scheduled stopping and starting an instance - python & cron
- AWS : Detecting stopped instance and sending an alert email using Mandrill smtp
- AWS : Elastic Beanstalk with NodeJS
- AWS : Elastic Beanstalk Inplace/Rolling Blue/Green Deploy
- AWS : Identity and Access Management (IAM) Roles for Amazon EC2
- AWS : Identity and Access Management (IAM) Policies, sts AssumeRole, and delegate access across AWS accounts
- AWS : Identity and Access Management (IAM) sts assume role via aws cli2
- AWS : Creating IAM Roles and associating them with EC2 Instances in CloudFormation
- AWS Identity and Access Management (IAM) Roles, SSO(Single Sign On), SAML(Security Assertion Markup Language), IdP(identity provider), STS(Security Token Service), and ADFS(Active Directory Federation Services)
- AWS : Amazon Route 53
- AWS : Amazon Route 53 - DNS (Domain Name Server) setup
- AWS : Amazon Route 53 - subdomain setup and virtual host on Nginx
- AWS Amazon Route 53 : Private Hosted Zone
- AWS : SNS (Simple Notification Service) example with ELB and CloudWatch
- AWS : Lambda with AWS CloudTrail
- AWS : SQS (Simple Queue Service) with NodeJS and AWS SDK
- AWS : Redshift data warehouse
- AWS : CloudFormation
- AWS : CloudFormation Bootstrap UserData/Metadata
- AWS : CloudFormation - Creating an ASG with rolling update
- AWS : Cloudformation Cross-stack reference
- AWS : OpsWorks
- AWS : Network Load Balancer (NLB) with Autoscaling group (ASG)
- AWS CodeDeploy : Deploy an Application from GitHub
- AWS EC2 Container Service (ECS)
- AWS EC2 Container Service (ECS) II
- AWS Hello World Lambda Function
- AWS Lambda Function Q & A
- AWS Node.js Lambda Function & API Gateway
- AWS API Gateway endpoint invoking Lambda function
- AWS API Gateway invoking Lambda function with Terraform
- AWS API Gateway invoking Lambda function with Terraform - Lambda Container
- Amazon Kinesis Streams
- AWS: Kinesis Data Firehose with Lambda and ElasticSearch
- Amazon DynamoDB
- Amazon DynamoDB with Lambda and CloudWatch
- Loading DynamoDB stream to AWS Elasticsearch service with Lambda
- Amazon ML (Machine Learning)
- Simple Systems Manager (SSM)
- AWS : RDS Connecting to a DB Instance Running the SQL Server Database Engine
- AWS : RDS Importing and Exporting SQL Server Data
- AWS : RDS PostgreSQL & pgAdmin III
- AWS : RDS PostgreSQL 2 - Creating/Deleting a Table
- AWS : MySQL Replication : Master-slave
- AWS : MySQL backup & restore
- AWS RDS : Cross-Region Read Replicas for MySQL and Snapshots for PostgreSQL
- AWS : Restoring Postgres on EC2 instance from S3 backup
- AWS : Q & A
- AWS : Security
- AWS : Security groups vs. network ACLs
- AWS : Scaling-Up
- AWS : Networking
- AWS : Single Sign-on (SSO) with Okta
- AWS : JIT (Just-in-Time) with Okta
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization