Hadoop Tutorial II : MapReduce Word Count
Continued from Hadoop Tutorial - Overview, this tutorial will show how to use hadoop with CDH 5 cluster on EC2.
We have 4 EC2 instances, one for Name node and three for Data nodes.
To see how MapReduce works, in this tutorial, we'll use an WordCount example. WordCount is a simple application that counts the number of occurrences of each word in an input set (code source Word Count):
package org.myorg;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
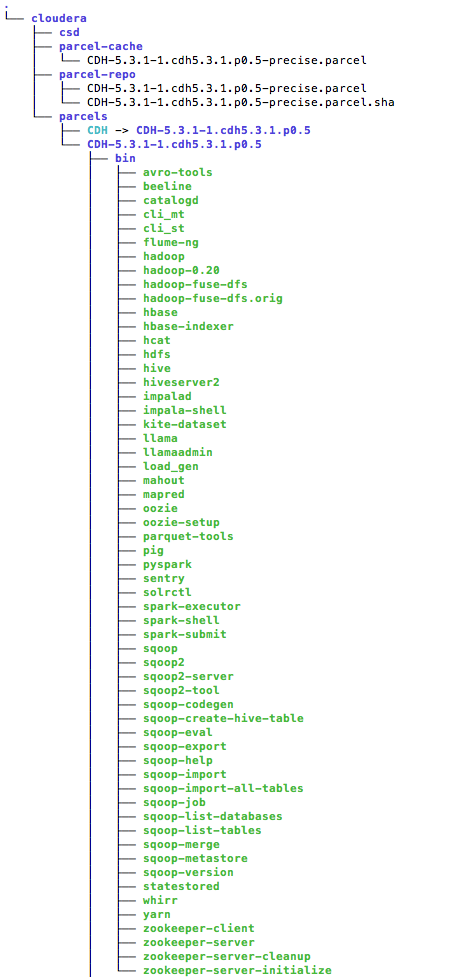
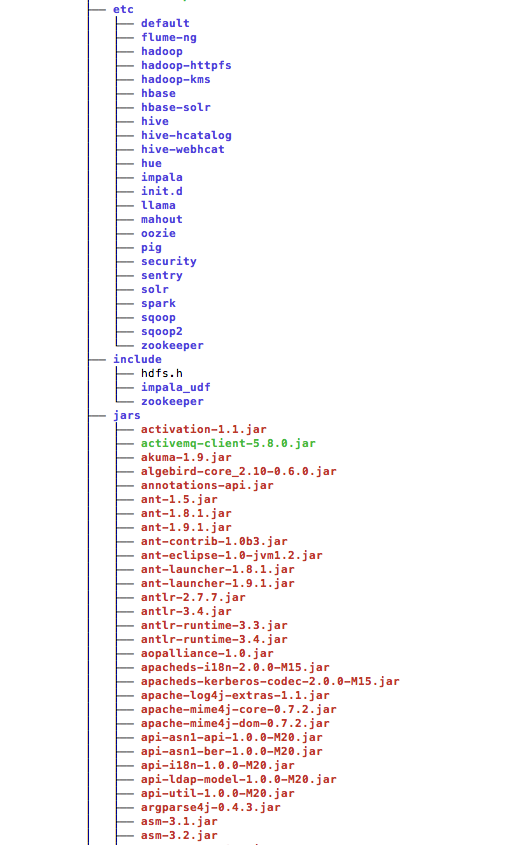
Here is the hadoop directory structure that Cloudera Manager constructed:
...

$ mkdir wordcount_classes
Compile:
$ javac -cp /opt/cloudera/parcels/CDH/lib/hadoop/*:/opt/cloudera/parcels/CDH/lib/hadoop/client-0.20/* -d wordcount_classes WordCount.java
$ jar -cvf wordcount.jar -C wordcount_classes/ . added manifest adding: WordCount$TokenizerMapper.class(in = 1736) (out= 754)(deflated 56%) adding: WordCount.class(in = 1501) (out= 811)(deflated 45%) adding: WordCount$IntSumReducer.class(in = 1739) (out= 739)(deflated 57%)
Create the input directory /user/cloudera/wordcount/input in HDFS:
$ sudo su hdfs $ hadoop fs -mkdir /user/cloudera $ hadoop fs -chown hdfs /user/cloudera $ hadoop fs -ls /user Found 6 items drwxr-xr-x - admin admin 0 2015-02-09 16:07 /user/admin drwxr-xr-x - hdfs supergroup 0 2015-02-10 16:39 /user/cloudera drwxr-xr-x - hdfs supergroup 0 2015-02-09 16:07 /user/hdfs drwxrwxr-t - hive hive 0 2015-02-09 15:35 /user/hive drwxrwxr-x - hue hue 0 2015-02-09 15:40 /user/hue drwxrwxr-x - oozie oozie 0 2015-02-09 15:37 /user/oozie $ hadoop fs -mkdir /user/cloudera/wordcount /user/cloudera/wordcount/input $ hdfs dfs -ls -R /user/cloudera drwxr-xr-x - hdfs supergroup 0 2015-02-10 16:39 /user/cloudera/wordcount drwxr-xr-x - hdfs supergroup 0 2015-02-10 16:39 /user/cloudera/wordcount/input
Create sample text files as input and move to the input directory:
$ echo "Hello World Bye World" > file0 $ echo "Hello Hadoop Goodbye Hadoop" > file1 $ whoami ubuntu $ sudo su hdfs $ hadoop fs -put file* /user/cloudera/wordcount/input $ hdfs dfs -cat /user/cloudera/wordcount/input/file0 Hello World Bye World $ hdfs dfs -cat /user/cloudera/wordcount/input/file1 Hello Hadoop Goodbye Hadoop
$ ls -la total 20 drwxrwxr-x 3 ubuntu ubuntu 4096 Feb 10 17:27 . drwxr-xr-x 5 ubuntu ubuntu 4096 Feb 10 15:00 .. drwxrwxr-x 2 ubuntu ubuntu 4096 Feb 10 15:00 wordcount_classes -rw-rw-r-- 1 ubuntu ubuntu 3071 Feb 10 15:08 wordcount.jar -rw-rw-r-- 1 ubuntu ubuntu 2089 Feb 10 15:00 WordCount.java $ whoami ubuntu $ sudo su hdfs $ hadoop jar wordcount.jar org.myorg.WordCount /user/cloudera/wordcount/input /user/cloudera/wordcount/output 15/02/10 17:24:25 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 15/02/10 17:24:26 INFO input.FileInputFormat: Total input paths to process : 2 15/02/10 17:24:28 INFO mapred.JobClient: Running job: job_201502101559_0001 15/02/10 17:24:29 INFO mapred.JobClient: map 0% reduce 0% 15/02/10 17:24:53 INFO mapred.JobClient: map 50% reduce 0% 15/02/10 17:24:57 INFO mapred.JobClient: map 100% reduce 0% 15/02/10 17:25:10 INFO mapred.JobClient: map 100% reduce 100% 15/02/10 17:25:17 INFO mapred.JobClient: Job complete: job_201502101559_0001 15/02/10 17:25:17 INFO mapred.JobClient: Counters: 32 15/02/10 17:25:18 INFO mapred.JobClient: File System Counters 15/02/10 17:25:18 INFO mapred.JobClient: FILE: Number of bytes read=79 15/02/10 17:25:18 INFO mapred.JobClient: FILE: Number of bytes written=613935 15/02/10 17:25:18 INFO mapred.JobClient: FILE: Number of read operations=0 15/02/10 17:25:18 INFO mapred.JobClient: FILE: Number of large read operations=0 15/02/10 17:25:18 INFO mapred.JobClient: FILE: Number of write operations=0 15/02/10 17:25:18 INFO mapred.JobClient: HDFS: Number of bytes read=282 15/02/10 17:25:18 INFO mapred.JobClient: HDFS: Number of bytes written=41 15/02/10 17:25:18 INFO mapred.JobClient: HDFS: Number of read operations=4 15/02/10 17:25:18 INFO mapred.JobClient: HDFS: Number of large read operations=0 15/02/10 17:25:18 INFO mapred.JobClient: HDFS: Number of write operations=1 15/02/10 17:25:18 INFO mapred.JobClient: Job Counters 15/02/10 17:25:18 INFO mapred.JobClient: Launched map tasks=2 15/02/10 17:25:18 INFO mapred.JobClient: Launched reduce tasks=1 15/02/10 17:25:18 INFO mapred.JobClient: Data-local map tasks=2 15/02/10 17:25:18 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=37607 15/02/10 17:25:18 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=11336 15/02/10 17:25:18 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 15/02/10 17:25:18 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 15/02/10 17:25:18 INFO mapred.JobClient: Map-Reduce Framework 15/02/10 17:25:18 INFO mapred.JobClient: Map input records=2 15/02/10 17:25:18 INFO mapred.JobClient: Map output records=8 15/02/10 17:25:18 INFO mapred.JobClient: Map output bytes=82 15/02/10 17:25:18 INFO mapred.JobClient: Input split bytes=232 15/02/10 17:25:18 INFO mapred.JobClient: Combine input records=8 15/02/10 17:25:18 INFO mapred.JobClient: Combine output records=6 15/02/10 17:25:18 INFO mapred.JobClient: Reduce input groups=5 15/02/10 17:25:18 INFO mapred.JobClient: Reduce shuffle bytes=101 15/02/10 17:25:18 INFO mapred.JobClient: Reduce input records=6 15/02/10 17:25:18 INFO mapred.JobClient: Reduce output records=5 15/02/10 17:25:18 INFO mapred.JobClient: Spilled Records=12 15/02/10 17:25:18 INFO mapred.JobClient: CPU time spent (ms)=2440 15/02/10 17:25:18 INFO mapred.JobClient: Physical memory (bytes) snapshot=880955392 15/02/10 17:25:18 INFO mapred.JobClient: Virtual memory (bytes) snapshot=5569368064 15/02/10 17:25:18 INFO mapred.JobClient: Total committed heap usage (bytes)=689274880
Examine the output:
$ hdfs dfs -ls -R /user/cloudera/wordcount drwxr-xr-x - hdfs supergroup 0 2015-02-10 16:55 /user/cloudera/wordcount/input -rw-r--r-- 3 hdfs supergroup 22 2015-02-10 16:55 /user/cloudera/wordcount/input/file0 -rw-r--r-- 3 hdfs supergroup 28 2015-02-10 16:55 /user/cloudera/wordcount/input/file1 drwxr-xr-x - hdfs supergroup 0 2015-02-10 17:25 /user/cloudera/wordcount/output -rw-r--r-- 3 hdfs supergroup 0 2015-02-10 17:25 /user/cloudera/wordcount/output/_SUCCESS drwxr-xr-x - hdfs supergroup 0 2015-02-10 17:24 /user/cloudera/wordcount/output/_logs drwxr-xr-x - hdfs supergroup 0 2015-02-10 17:24 /user/cloudera/wordcount/output/_logs/history -rw-r--r-- 3 hdfs supergroup 21818 2015-02-10 17:25 /user/cloudera/wordcount/output/_logs/history/job_201502101559_0001_1423589067550_hdfs_word+count -rw-r--r-- 3 hdfs supergroup 96178 2015-02-10 17:24 /user/cloudera/wordcount/output/_logs/history/job_201502101559_0001_conf.xml -rw-r--r-- 3 hdfs supergroup 41 2015-02-10 17:25 /user/cloudera/wordcount/output/part-r-00000 $ hdfs dfs -cat /user/cloudera/wordcount/output/part-r-00000 Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2
We can see the tasks have been splitted among the DataNodes:
$ hdfs dfs -cat /user/cloudera/wordcount/output/_logs/history/job_201502101559_0001_1423589067550_hdfs_word+count ... Task TASKID="task_201502101559_0001_m_000000" TASK_TYPE="MAP" START_TIME="1423589082327" SPLITS="/default/hd1,/default/hd2,/default/hd3" . Task TASKID="task_201502101559_0001_m_000001" TASK_TYPE="MAP" START_TIME="1423589082420" SPLITS="/default/hd2,/default/hd3,/default/hd1" . ...
From Walk-through.
- The Mapper implementation,map method , processes one line of the an input at a time.
- It then splits the line into tokens separated by whitespace, via the StringTokenizer, and emits a key-value pair of <word, 1>.
- For the given sample input
the first map emits: <Hello, 1> <World, 1> <Bye, 1> <World, 1>
and 2nd map emits: <Hello, 1> <Hadoop, 1> <Goodbye, 1> <Hadoop, 1> - WordCount also specifies a combiner. Hence, the output of each map is passed through the local combiner (which is same as the Reducer as per the job configuration) for local aggregation, after being sorted on the keys.
- The output of the first map: <Bye, 1> <Hello, 1> <World, 2>
The output of the 2nd map: <Goodbye, 1> <Hadoop, 2> <Hello, 1>
- The Reducer implementation,
reduce method just sums up the values, which are the occurrence counts for each key. - So, the output of the job is: <Bye, 1> <Goodbye, 1> <Hadoop, 2> <Hello, 2> <World, 2>
- The run method specifies various facets of the job, such as the input/output paths (passed via the command line), key-value types, input/output formats etc., in the JobConf.
- It then calls the JobClient.runJob to submit the and monitor its progress.
Big Data & Hadoop Tutorials
Hadoop 2.6 - Installing on Ubuntu 14.04 (Single-Node Cluster)
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)
Hadoop - Running MapReduce Job
Hadoop - Ecosystem
CDH5.3 Install on four EC2 instances (1 Name node and 3 Datanodes) using Cloudera Manager 5
CDH5 APIs
QuickStart VMs for CDH 5.3
QuickStart VMs for CDH 5.3 II - Testing with wordcount
QuickStart VMs for CDH 5.3 II - Hive DB query
Scheduled start and stop CDH services
CDH 5.8 Install with QuickStarts Docker
Zookeeper & Kafka Install
Zookeeper & Kafka - single node single broker
Zookeeper & Kafka - Single node and multiple brokers
OLTP vs OLAP
Apache Hadoop Tutorial I with CDH - Overview
Apache Hadoop Tutorial II with CDH - MapReduce Word Count
Apache Hadoop Tutorial III with CDH - MapReduce Word Count 2
Apache Hadoop (CDH 5) Hive Introduction
CDH5 - Hive Upgrade to 1.3 to from 1.2
Apache Hive 2.1.0 install on Ubuntu 16.04
Apache Hadoop : HBase in Pseudo-Distributed mode
Apache Hadoop : Creating HBase table with HBase shell and HUE
Apache Hadoop : Hue 3.11 install on Ubuntu 16.04
Apache Hadoop : Creating HBase table with Java API
Apache HBase : Map, Persistent, Sparse, Sorted, Distributed and Multidimensional
Apache Hadoop - Flume with CDH5: a single-node Flume deployment (telnet example)
Apache Hadoop (CDH 5) Flume with VirtualBox : syslog example via NettyAvroRpcClient
List of Apache Hadoop hdfs commands
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 1
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 2
Apache Hadoop : Creating Card Java Project with Eclipse using Cloudera VM UnoExample for CDH5 - local run
Apache Hadoop : Creating Wordcount Maven Project with Eclipse
Wordcount MapReduce with Oozie workflow with Hue browser - CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM
Spark 1.2 using VirtualBox and QuickStart VM - wordcount
Spark Programming Model : Resilient Distributed Dataset (RDD) with CDH
Apache Spark 1.2 with PySpark (Spark Python API) Wordcount using CDH5
Apache Spark 1.2 Streaming
Apache Spark 2.0.2 with PySpark (Spark Python API) Shell
Apache Spark 2.0.2 tutorial with PySpark : RDD
Apache Spark 2.0.0 tutorial with PySpark : Analyzing Neuroimaging Data with Thunder
Apache Spark Streaming with Kafka and Cassandra
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization