Apache Drill - Query Hive
Apache Hive is a client side library providing a table like abstraction on top of the data in HDFS for data processing. Hive jobs are converted into a MR plan which is then submitted to the Hadoop cluster for execution.
The Hive table definitions and mapping to the data are stored in a metastore. Metastore constitutes of
- meta store service.
- database.
The metastore service provides the interface to the Hive and the database stores the data definitions, mappings to the data.
We can run Hive queries in two ways by configuring the Hive storage plugin.
- Connect to the Hive embedded metastore, and this is the default Hive configuration (as is from Apache Hive without any configuration changes). With this configuration, the Hive driver, metastore interface and the db (derby) all use the same JVM. This is good only for the development stage and it is mainly used for unit tests.
Since only one process can connect to the metastore database at a time, it is not really a practical solution and it won't scale to a production environment.
Derby is the default database for the embedded metastore and the configuration looks like this:{ "type": "hive", "enabled": true, "configProps": { "hive.metastore.uris": "", "javax.jdo.option.ConnectionURL": "jdbc:derby:;databaseName=../sample-data/drill_hive_db;create=true", "hive.metastore.warehouse.dir": "/tmp/drill_hive_wh", "fs.default.name": "file:///", "hive.metastore.sasl.enabled": "false" } }
- Connect Drill to the Hive local metastore. It uses an external database which is JDBC compliant.
- Connect Drill to the Hive remote metastore. In this configuration, we would use a traditional standalone RDBMS server. The Hive driver and the metastore interface would be running in a different JVM (which can run on different machines also). This way the database can be fire-walled from the Hive user and also database credentials are completely isolated from users of Hive.
In this tutorial, we'll learn how to create a Hive table and insert data that we can query using Drill.
For more info about Hive and how to install it, visit Install Apache Hive on Ubuntu 16.04.
We need hadoop and hive. Here is the tutorials how to install and configure those:
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)Apache Hive 2.1.0 install on Ubuntu 16.04
To access Hive tables using custom SerDes (Serializer, Deserializer) or InputFormat/OutputFormat, all nodes running Drillbits must have the corresponding JAR files in the <drill_installation_directory>/jars/3rdparty folder.
To view or change the Hive storage plugin configuration, we want to use the Drill Web Console.
Run Drill:
root@laptop:/usr/local/apache-drill-1.8.0# bin/drill-embedded 0: jdbc:drill:zk=local>
In the Web Console (localhost:8047), select the Storage tab, and then click the Update button for the hive storage plugin configuration:
The following is the default HBase storage plugin, and we'll use it as it is:
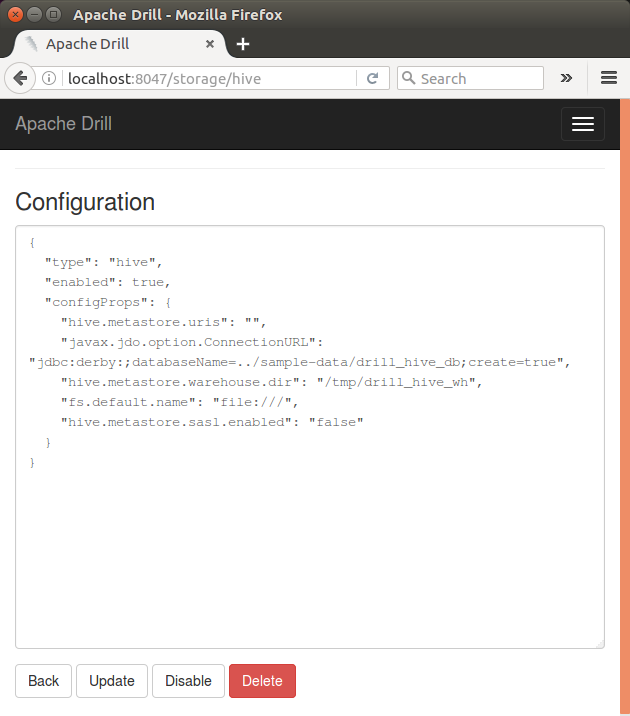
Click "Enable" and "Back", then we can see the HBase plugin has been enabled:
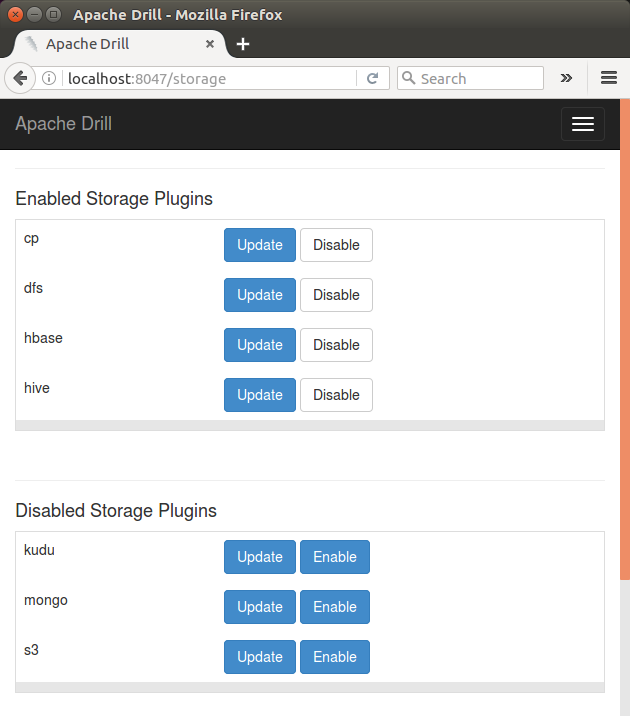
After configuring a Hive storage plugin, we can query Hive tables.
To create a Hive table by following the the steps below:
- We need to download customers.csv
- First, we need to start a Hive shell:
hduser@laptop:/usr/local/apache-hive-2.1.0-bin/bin$ hive SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.1.0-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] ... hive>
- Let's create a table schema:
hive> create table customers(FirstName string, LastName string, Company string, Address string, City string, County string, State string, Zip string, Phone string, Fax string, Email string, Web string) row format delimited fields terminated by ',' stored as textfile; OK Time taken: 10.599 seconds hive>
- Load the customer data into the customers table:
hive> load data local inpath '/tmp/customers.csv' overwrite into table customers; Loading data to table default.customers OK Time taken: 5.913 seconds
- The describe command provides information about the schema of the table:
hive> describe default.customers; OK firstname string lastname string company string address string city string county string state string zip string phone string fax string email string web string Time taken: 3.161 seconds, Fetched: 12 row(s)
Note that we can use just the table name without the "default" : describe customers;
- To see some of the contents of the table:
hive> select FirstName, LastName from customers limit 5; OK FirstName LastName Essie Vaill Cruz Roudabush Billie Tinnes Zackary Mockus Time taken: 11.308 seconds, Fetched: 5 row(s)
- Exit to leave the Hive shell:
hive> exit;
- Start the Drill shell:
root@laptop:/usr/local/apache-drill-1.8.0# bin/drill-embedded ... apache drill 1.8.0 ... 0: jdbc:drill:zk=local>
- Lets' see how to use a file system and a hive schema to query a file and table in Drill.
Issue the show databases or show schemas command to see a list of the available schemas that we can use. Both commands return the same results:0: jdbc:drill:zk=local> show databases; +---------------------+ | SCHEMA_NAME | +---------------------+ | INFORMATION_SCHEMA | | cp.default | | dfs.default | | dfs.root | | dfs.tmp | | hbase | | hive.default | | sys | +---------------------+ 8 rows selected (0.596 seconds) 0: jdbc:drill:zk=local> show schemas; +---------------------+ | SCHEMA_NAME | +---------------------+ | INFORMATION_SCHEMA | | cp.default | | dfs.default | | dfs.root | | dfs.tmp | | hbase | | hive.default | | sys | +---------------------+ 8 rows selected (1.494 seconds) 0: jdbc:drill:zk=local>
- Type the command use hive to make Drill use Hive schema:
0: jdbc:drill:zk=local> use hive; +-------+-----------------------------------+ | ok | summary | +-------+-----------------------------------+ | true | Default schema changed to [hive] | +-------+-----------------------------------+ 1 row selected (0.421 seconds) 0: jdbc:drill:zk=local>
- Type the command show tables to see the tables that exist within the schema:
0: jdbc:drill:zk=local> show tables; +---------------+-------------+ | TABLE_SCHEMA | TABLE_NAME | +---------------+-------------+ +---------------+-------------+ No rows selected (1.058 seconds) 0: jdbc:drill:zk=local>
Here, we're supposed to see "customers" table but no tables in "hive". We need to fix this. - Let's fix the metastore issue.
Add the line highlighted in green to conf/hive-site.xml file:
<property> <name>hive.metastore.uris</name> <value>thrift://localhost:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property>
Then, start the Hive Metastore Server using hive --service metastore command:hduser@laptop:/usr/local/apache-hive-2.1.0-bin$ hive --service metastore Starting Hive Metastore Server SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/apache-hive-2.1.0-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Note that we are running hive metastore as a separate service (outside hive).
While the Hive Metastore Server is running, let's configure Drill for hive (http://localhost:8047/storage/hive):{ "type": "hive", "enabled": true, "configProps": { "hive.metastore.uris": "thrift://localhost:9083", "fs.default.name": "hdfs://localhost:54313/", "hive.metastore.sasl.enabled": "false" } }
Click "Update".
Here, we can find the fs.default.name using either one of the two commands as shown below:hduser@laptop:~$ hdfs getconf -confKey fs.default.name hdfs://localhost:54310 hduser@laptop:~$ hdfs getconf -confKey fs.defaultFS hdfs://localhost:54310
Then, we may want to go back to our Drill shell and check if hive schema is there either via show databases or show schemas command:
0: jdbc:drill:zk=local> show databases; +---------------------+ | SCHEMA_NAME | +---------------------+ | INFORMATION_SCHEMA | | cp.default | | dfs.default | | dfs.root | | dfs.tmp | | hbase | | hive.default | | sys | +---------------------+
- Now, it should work. Type the command show tables to see the tables that exist within the schema:
0: jdbc:drill:zk=local> use hive; +-------+-----------------------------------+ | ok | summary | +-------+-----------------------------------+ | true | Default schema changed to [hive] | +-------+-----------------------------------+ 1 row selected (0.44 seconds) 0: jdbc:drill:zk=local> show tables; +---------------+-------------+ | TABLE_SCHEMA | TABLE_NAME | +---------------+-------------+ | hive.default | customers | +---------------+-------------+ 1 row selected (5.71 seconds)
- Finally, we're ready to make a query with Drill:
0: jdbc:drill:zk=local> select FirstName, LastName from customers limit 5; +------------+------------+ | FirstName | LastName | +------------+------------+ | FirstName | LastName | | Essie | Vaill | | Cruz | Roudabush | | Billie | Tinnes | | Zackary | Mockus | +------------+------------+ 5 rows selected (12.304 seconds)
Big Data & Drill Tutorials
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization