bash

Linux - system, cmds & shell
- Linux Tips - links, vmstats, rsync
- Linux Tips 2 - ctrl a, curl r, tail -f, umask
- Linux - bash I
- Linux - bash II
- Linux - Uncompressing 7z file
- Linux - sed I (substitution: sed 's///', sed -i)
- Linux - sed II (file spacing, numbering, text conversion and substitution)
- Linux - sed III (selective printing of certain lines, selective definition of certain lines)
- Linux - 7 File types : Regular, Directory, Block file, Character device file, Pipe file, Symbolic link file, and Socket file
- Linux shell programming - introduction
- Linux shell programming - variables and functions (readonly, unset, and functions)
- Linux shell programming - special shell variables
- Linux shell programming : arrays - three different ways of declaring arrays & looping with $*/$@
- Linux shell programming : operations on array
- Linux shell programming : variables & commands substitution
- Linux shell programming : metacharacters & quotes
- Linux shell programming : input/output redirection & here document
- Linux shell programming : loop control - for, while, break, and break n
- Linux shell programming : string
- Linux shell programming : for-loop
- Linux shell programming : if/elif/else/fi
- Linux shell programming : Test
- Managing User Account - useradd, usermod, and userdel
- Linux Secure Shell (SSH) I : key generation, private key and public key
- Linux Secure Shell (SSH) II : ssh-agent & scp
- Linux Secure Shell (SSH) III : SSH Tunnel as Proxy - Dynamic Port Forwarding (SOCKS Proxy)
- Linux Secure Shell (SSH) IV : Local port forwarding (outgoing ssh tunnel)
- Linux Secure Shell (SSH) V : Reverse SSH Tunnel (remote port forwarding / incoming ssh tunnel) /)
- Linux Processes and Signals
- Linux Drivers 1
- tcpdump
- Linux Debugging using gdb
- Embedded Systems Programming I - Introduction
- Embedded Systems Programming II - gcc ARM Toolchain and Simple Code on Ubuntu/Fedora
- LXC (Linux Container) Install and Run
- Linux IPTables
- Hadoop - 1. Setting up on Ubuntu for Single-Node Cluster
- Hadoop - 2. Runing on Ubuntu for Single-Node Cluster
- ownCloud 7 install
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox I
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox II
- Windows 8 guest on Mac OSX host using VirtualBox I
- Ubuntu Package Management System (apt-get vs dpkg)
- RPM Packaging
- How to Make a Self-Signed SSL Certificate
- Linux Q & A
- DevOps / Sys Admin questions
A shell is a special-purpose program designed to read commands typed by a user and execute appropriate programs in response to those commands. Such a program is sometimes known as a command interpreter - definition from "Linux Programming Interface".
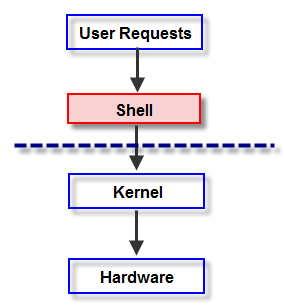
The login shell is used to denote the process created to run a shell when the user first logs in.
While on some OS, the command interpreter is a part of kernel, on UNIX, the shell is a user process. There can be many different shells exists, and different uses on the same computer can simultaneously use different shells.
The shells are designed
- not just for interactive use,
- but also for the interpretation of shell scripts.
The Bourne Again Shell and TC Shell (tcsh) are command interpreters and high-level programming languages. Most system shell scripts are written to run under bash.
When a shell starts, it runs startup files to initialize itself. Which files the shell runs depends on whether it is a login shell, an interactive shell that is not a login shell.
login shells - The shell first executes the commands in /etc/profile. Then, the shell looks for ~/.bash_profile, ~/.bash_login, and ~/.profile. We can put commands in one of these files to override the defaults set in /etc/profile. When we log out, bash executes commands in the ~/.bash_logout file.
In other words, when we do login (type username and password) via console, either sitting at the machine, or remotely via ssh: .bash_profile is executed to configure our shell before the initial command prompt.
However, if we've already logged into our machine and open a new terminal window (xterm), then .bashrc is executed before the window command prompt. That why we do source .bashrc to change the shell behavior after we modified the file. The .bashrc is also run when we start a new bash instance by typing /bin/bash in a terminal.
Why the two different files?
- ~/.bash_profile is the place to put stuff that applies to our whole session, such as programs that we want to start when we log in, and environment variable definitions.
- ~/.bashrc is the place to put stuff that applies only to bash itself, such as alias and function definitions, shell options, and prompt settings.
-
interactive nonlogin shells - These shells inherit values from the login shell variables that are set by starup files. Although not called by bash directly, many ~/.bashrc files call /etc/bashrc. This setup allows a super user to establish systemwide default characteritics for nonlogin bash shells. An interactive nonlogin shell executes commands in the ~/.bashrc file. Typically, a startup file for a login shell, such as .bashrc_profile, runs this file, so both login and nonlogin shells run the commands in .bashrc
startup files - .bash_profile and .bashrc file.
Commands similar to the following in .bash_profile run commands from .bashrc for login shells. With this setup, the commands in .bashrc are executed by login and nonlogin shells:if [ -f ~/.bashrc ]; then . ~/.bashrc; fi
Here, [ -f ~/.bashrc ] tests whether the file named .bashrc in our home directory exists. Modifying a variable in .bash_profile propagate to subshells. However, modifying a variable in .bashrc overrides changes inherited from a parent shell. When we put our command in .bash_profile and not in .bashrc, the command executed only once, when we log in.
Let's look at some examples. In a starup file, we must export variables and functions that we want to be available to child processes.
# ~/.bash_profile if [ -f ~/.bashrc ]; then . ~/.bashrc # Read local startup file if it exists fi PATH=$PATH:$HOME/bin export PS1='[\W \!]\$ ' # Set promptThe first command executes the commands in the user's .bashrc file if it exists. Then, it adds to the PATH variable. In general, PATH is set and exported in /etc/profile so it does not need to be exported in a user's startup file. The last command sets and exports PS1, which controls the user's prompt.
As an example for .bashrc file looks like this:
# Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc # read global startup file if it exists fi # User specific aliases and functions set -o noclobber # prevent overwriting files unset MAILCHECK # turn off mail notice export LANG=C # set LANG variable export VIMINIT # set vim options alias df='df -h' alias rm='rm -i' alias lt='ls -lrt | tail' alias h='history | tail'The first command executes the commands in the /etc/bashrc file if it exists. Then, the file sets and exports the LANGVIMINIT variables and defines aliases. ls -lrt shows the list sorted by modification time in reverse order, putting the most recent one at the bottom.
-
We can run the startup file using .(dot) or source. In this case, the changes we make to variables from within the script affect the shell we run the script from. If we ran a startup file as a regular shell script and did not use .(dot) or source, the variables created in the startup file would remain in effect only in the subshell running the script-not in the shell we ran the script from.
$ cat ~/.bashrc ..... # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc # read global startup file if it exists fi ..... $ . ~/.bashrc - Symbol commands
Symbol Comamnd () Subshell $() Command substitution (()) Arithmetic evaluation $(()) Arithmetic expansion [] Test command [[]] Conditional expression; similar to [] but adds string comparisons
Commands can send output to standard error. By default, the shell directs standard error to the screen. So, unless we redirect, we may not know the difference between the output a command sends to standard output and the output it sends to standard error.
Before a file can be read from or written to, it must be opened. The kernel maintains a list of open files for each process. The list is called file table. The table is indexed via non-negative integers known as file descriptor. Each entry in the list contains information about an open file. Opening a f returns a file descriptor, and reading/writing take the file descriptor as an argument.
File descriptors are the places a program sends its output to and gets its input from. File descriptors are shared with user space, and are used directly by user programs to access files. When we execute a program, Linux opens three file descriptors for the program:
- 0 standard input (stdin)
- 1 standard output (stdout)
- 2 standard error (stderr)
The redirect output symbol ( >) is shorthand for 1>, which tells the shell to redirect standard output. Similarly, < is short for 0<, which redirects standard input. The symbol 2> redirects standard error.
In the examples below, we'll see how to redirect standard output and standard error to different files and to the same file. When we run the cat with the name of a file that does not exist and the name of a file that does exist, cat sends an error message to standard error and copies the file that does exist to standard output. Unless we redirect them, both messages appear on the screen.
$ cat file1 This is file 1 $ cat file2 cat: file2: No such file or directory $ $ cat file1 file2 This is file 1 cat: file2: No such file or directory
When we redirect standard output, the output sent to standard error is not affected and still appears on the screen:
$ cat file1 file2 > out cat: file2: No such file or directory $ cat out This is file 1
Similarly, when we send standard output through a pipe, standard error is not affected. The example below send standard output of cat through a pipe to tr, which converts lowercase to uppercase. The text that cat sends to standard error is not translated because it goes directly to the screen rather than through the pipe.
$ cat file1 file2 | tr "[a-z]" "[A-Z]" cat: file2: No such file or directory THIS IS FILE 1
The next example redirects standard output and standard error to different files. The token following 2> tells the shell where to redirect standard error, file descriptor 2. The token following 1> tells the shell where to redirect the standard output, file descriptor 1. We can use > in place of 1>.
$ cat file1 file2 1>std_out 2> err_out $ cat std_out This is file 1 $ cat err_out cat: file2: No such file or directory
In the following example, the &> token redirects standard output and standard error to a single file. The >& token does the same thing under tcsh.
$ cat file1 file2 &> std_err_out $ cat std_err_out This is file 1 cat: file2: No such file or directory
In the example below, first 1> redirects standard output to std_out and the 2>&1 declares file descriptor 2 to be a duplicate of file descriptor 1. As a result, both standard output and standard error are redirected to std_out.
$ cat file1 file2 1> std_out 2>&1 $ cat std_out This is file 1 cat: file2: No such file or directory
In 2>&1, we may want to keep the order for redirection, otherwise we may not get the expected result.
The following example declares file descriptor to be a duplicate of the file descriptor 1 and sends the output for file descriptor 1 through a pipe to the tr command.
$ cat file1 file2 2>&1 | tr "[a-z]" "[A-Z]" THIS IS FILE 1 CAT: FILE2: NO SUCH FILE OR DIRECTORY
If we do not want to save the output, we can send it to /dev/null:
$ kill -1 26732 > /dev/null 2>&1
The shell interprets and executes the commands in a shell script, one after another. So, a shell script enables us to simply and quickly initiate a complex series of tasks or a repetitive procedure.
We can put a special sequence of characters on the first line of a shell script to tell the OS which shell should execute the file. Actually, OS checks the initial characters of a program before anything else. If #! are the first two characters, the system interprets the characters that follow as the absolute pathname of the utility that should execute the script. This can be the pathname of any program, not just a shell. The example below specifies that bash should run the script:
#!/bin/bash
To tell the OS that tcsh should run the script, we do this:
#!/bin/tcsh
Because of the #! line, the OS ensures that tcsh executes the script no matter which shell we run it from.
A command on the command causes the shell to fork a new process, creating a duplicate of the shell process, a subshell. The new process to execute the command (exec). The exec routine, like fork, is executed by the system call. If the command is a binary executable, exec succeeds and the system overlays the newly created subshell with the executable. If the command is a shell script, exec fails. When exec fails, the command is assumed to be a shell script, and the subshell runs the commands in the script. Unlike a login shell, which expects input from the command line, the subshell takes its input from a file, the shell script.
We can run commands in a shell script file that we do not have execute permission for by using a bash command to exec a shell that runs the script directly. In the example below, bash creates a new shell that takes its input from the file named my_script:
$ bash my_script
Because the bash command expects to read a file containing commands, we do not need execute permission for my_script. Even though bash reads and executes the commands in my_script, standard input, standard output, and standard error remain directed from/to the terminal.
We can use bash to execute a shell script, however, it's slower than directly invoking the script. But there are cases when bash is not our interactive shell or we want to see how the script runs with different shells, we may want to run a script as an argument to bash or tcsh.
Although files are usually accessed via filename, they are not directly associated with such names. Instead, a file is referenced by an inode (information node), which is assigned a unique numeric value. This value is called the inode number (i-number, ino). An inode stores metadata associated with a file, such as its modification time stamp, owner, type, length, and the location of the file's data, but no file name. Accessing a file via its inode number is cumbersome, so files are always opened from user space by a name , not an inode number.
Directories are used to provide the names with which to access files. A directory acts as a mapping of names to inode numbers. A name and inode pair is called a link. The physical on-disk form of this mapping may be implemented via a simple table or a hash, and managed by the kernel code that supports a given file system. Conceptually, a directory is viewed like any normal file, with the difference that it contains only a mapping of names to inodes. The kernel directly uses this mapping to perform name-to-inode resolutions.
When a user-space application requests that a given filename be opened, the kernel opens the directory containing the filename and searches for the given name. From the filename, the kernel obtains the inode number. The inode contains metadata associated with the file, including the on-disk location of the file's data.
We can store a list (stack) of directories we are working with, enabling us to move easily.
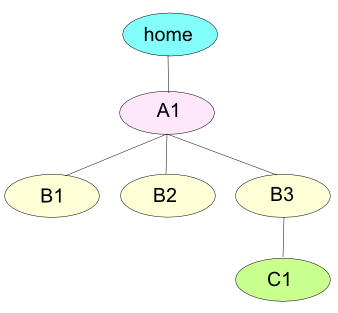
The dirs displays the contents of the directory stack. If we use dirs when the directory stack is empty, it displays the name of the working directory:
$ dirs~/A1/B3
- When we do pushd with one argument, it pushes the directory specified by the argument on the stack, changes directories to the specified directory, and displays the stack:
[B3]$ pushd ../B1 ~/A1/B1 ~/A1/B3 [B1]$ pwd /home/A1/B1 [B1]$ pushd ../B2 ~/A1/B2 ~/A1/B1 ~/A1/B3 [B2]$ pwd /home/A1/B2
When we use pushd without any argument, it swaps the top two directories on the stack, makes the new top directory (which was the second directory) the new working directory, and displays the stack:
[B2]$ pushd ~/A1/B1 ~/A1/B2 ~/A1/B3 [B1]$ pwd /home/A1/B1
-
To remove a directory from the stack, we can use the popd. If we use popd without any argument, popd removes the top directory from the stack and changes the working directory to the new top directory:
[B1]$ dirs ~/A1/B1 ~/A1/B2 ~/A1/B3 [B1]$ pwd /home/A1/B1 [B1]$ popd ~/A1/B2 ~/A1/B3 [B2]$ pwd /home/A1/B2
Linux - system, cmds & shell
- Linux Tips - links, vmstats, rsync
- Linux Tips 2 - ctrl a, curl r, tail -f, umask
- Linux - bash I
- Linux - bash II
- Linux - Uncompressing 7z file
- Linux - sed I (substitution: sed 's///', sed -i)
- Linux - sed II (file spacing, numbering, text conversion and substitution)
- Linux - sed III (selective printing of certain lines, selective definition of certain lines)
- Linux - 7 File types : Regular, Directory, Block file, Character device file, Pipe file, Symbolic link file, and Socket file
- Linux shell programming - introduction
- Linux shell programming - variables and functions (readonly, unset, and functions)
- Linux shell programming - special shell variables
- Linux shell programming : arrays - three different ways of declaring arrays & looping with $*/$@
- Linux shell programming : operations on array
- Linux shell programming : variables & commands substitution
- Linux shell programming : metacharacters & quotes
- Linux shell programming : input/output redirection & here document
- Linux shell programming : loop control - for, while, break, and break n
- Linux shell programming : string
- Linux shell programming : for-loop
- Linux shell programming : if/elif/else/fi
- Linux shell programming : Test
- Managing User Account - useradd, usermod, and userdel
- Linux Secure Shell (SSH) I : key generation, private key and public key
- Linux Secure Shell (SSH) II : ssh-agent & scp
- Linux Secure Shell (SSH) III : SSH Tunnel as Proxy - Dynamic Port Forwarding (SOCKS Proxy)
- Linux Secure Shell (SSH) IV : Local port forwarding (outgoing ssh tunnel)
- Linux Secure Shell (SSH) V : Reverse SSH Tunnel (remote port forwarding / incoming ssh tunnel) /)
- Linux Processes and Signals
- Linux Drivers 1
- tcpdump
- Linux Debugging using gdb
- Embedded Systems Programming I - Introduction
- Embedded Systems Programming II - gcc ARM Toolchain and Simple Code on Ubuntu/Fedora
- LXC (Linux Container) Install and Run
- Linux IPTables
- Hadoop - 1. Setting up on Ubuntu for Single-Node Cluster
- Hadoop - 2. Runing on Ubuntu for Single-Node Cluster
- ownCloud 7 install
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox I
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox II
- Windows 8 guest on Mac OSX host using VirtualBox I
- Ubuntu Package Management System (apt-get vs dpkg)
- RPM Packaging
- How to Make a Self-Signed SSL Certificate
- Linux Q & A
- DevOps / Sys Admin questions
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization