Docker & Kubernetes : Deploying Memcached on Kubernetes Engine - 2020
In this post, we'll learn how to deploy a cluster of distributed Memcached servers on Google Kubernetes Engine using Helm, and Mcrouter.
Memcached is a popular open source, multi-purpose caching system. It usually serves as a temporary store for frequently used data to speed up web applications and lighten database loads.
We'll:
- Learn about some characteristics of Memcached's distributed architecture.
- Deploy a Memcached service to GKE using Kubernetes and Helm.
- Deploy Mcrouter, an open source Memcached proxy, to improve the system's performance.
Redis and Memcached are popular, open-source, in-memory data stores.
Although they are both easy to use and offer high performance, there are important differences to consider when choosing an engine.
Memcached is designed for simplicity while Redis offers a rich set of features that make it effective for a wide range of use cases.
Which solution is better? It depends on our needs. But, Redis, the newer and more versatile of the two, is almost always the better choice.
Check Redis vs Memcached
Google Cloud Shell is loaded with development tools and it offers a persistent 5GB home directory and runs on the Google Cloud. Google Cloud Shell provides command-line access to our GCP resources. We can activate the shell: in GCP console, on the top right toolbar, click the Open Cloud Shell button:

In the dialog box that opens, click "START CLOUD SHELL".
gcloud is the command-line tool for Google Cloud Platform. It comes pre-installed on Cloud Shell and supports tab-completion.
Run the following command to create a Kubernetes cluster with 3 nodes:
$ gcloud container clusters create demo-cluster --num-nodes 3 --zone us-central1-f ... kubeconfig entry generated for demo-cluster. NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS demo-cluster us-central1-f 1.11.7-gke.4 104.198.60.249 n1-standard-1 1.11.7-gke.4 3 RUNNING

We want to deploy a Memcached service to GKE using a Helm chart with the following steps:
Download the helm binary archive:
$ cd ~ $ wget https://kubernetes-helm.storage.googleapis.com/helm-v2.6.0-linux-amd64.tar.gz
Unzip the archive file to our local system:
$ mkdir helm-v2.6.0 $ tar zxfv helm-v2.6.0-linux-amd64.tar.gz -C helm-v2.6.0
Add the helm binary's directory to our PATH environment variable:
$ export PATH="$(echo ~)/helm-v2.6.0/linux-amd64:$PATH"
This command makes the helm binary discoverable from any directory during the current Cloud Shell session. To make this configuration persist across multiple sessions, add the command to our Cloud Shell user's ~/.bashrc file.
Create a service account with the cluster admin role for Tiller, the Helm server:
$ kubectl create serviceaccount --namespace kube-system tiller serviceaccount "tiller" created $ kubectl create clusterrolebinding tiller --clusterrole=cluster-admin --serviceaccount=kube-system:tiller clusterrolebinding.rbac.authorization.k8s.io "tiller" created
Initialize Tiller in your cluster and update information of available charts:
$ helm init --service-account tiller ... Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster. Happy Helming! $ helm repo update Hang tight while we grab the latest from your chart repositories... ...Skip local chart repository ...Successfully got an update from the "stable" chart repository Update Complete. ⎈ Happy Helming!⎈
Install a new Memcached Helm chart release with three replicas, one for each node:
$ helm install stable/memcached --name mycache --set replicaCount=3 ==> v1/Service NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE mycache-memcached None <none> 11211/TCP 0s ==> v1beta1/StatefulSet NAME DESIRED CURRENT AGE mycache-memcached 3 1 0s NOTES: Memcached can be accessed via port 11211 on the following DNS name from within your cluster: mycache-memcached.default.svc.cluster.local If you'd like to test your instance, forward the port locally: export POD_NAME=$(kubectl get pods --namespace default -l "app=mycache-memcached" -o jsonpath="{.items[0].metadata.name}") kubectl port-forward $POD_NAME 11211 In another tab, attempt to set a key: $ echo -e 'set mykey 0 60 5\r\nhello\r' | nc localhost 11211 You should see: STORED
The Memcached Helm chart uses a StatefulSet controller. One benefit of using a StatefulSet controller is that the pods' names are ordered and predictable. In this case, the names are mycache-memcached-{0..2}. This ordering makes it easier for Memcached clients to reference the servers.
To see the running pods, run the following command:
$ kubectl get pods NAME READY STATUS RESTARTS AGE mycache-memcached-0 1/1 Running 0 1m mycache-memcached-1 1/1 Running 0 1m mycache-memcached-2 1/1 Running 0 1m
The Memcached Helm chart uses a headless service. A headless service exposes IP addresses for all of its pods so that they can be individually discovered.
Verify that the deployed service is headless:
$ kubectl get service mycache-memcached -o jsonpath="{.spec.clusterIP}" NoneThe output None confirms that the service has no clusterIP and that it is therefore headless.
The service creates a DNS record for a hostname of the form:
[SERVICE_NAME].[NAMESPACE].svc.cluster.local
In this post, the service name is mycache-memcached. Because a namespace was not explicitly defined, the default namespace is used, and therefore the entire host name is mycache-memcached.default.svc.cluster.local. This hostname resolves to a set of IP addresses and domains for all three pods exposed by the service. If, in the future, some pods get added to the pool, or old ones get removed, kube-dns will automatically update the DNS record.
It is the client's responsibility to discover the Memcached service endpoints, as described in the next steps.
Retrieve the endpoints' IP addresses:
$ kubectl get endpoints mycache-memcached NAME ENDPOINTS AGE mycache-memcached 10.40.0.5:11211,10.40.1.11:11211,10.40.2.7:11211 4m
Notice that each Memcached pod has a separate IP address, respectively 10.40.0.5, 10.40.1.11, and 10.40.2.7 and each pod listens to port 11211, which is Memcached's default port.
-
Alternatively, we can retrieve those same records using a standard DNS query with the nslookup command:
$ kubectl run -it --rm alpine --image=alpine:3.6 --restart=Never nslookup mycache-memcached.default.svc.cluster.local ... Name: mycache-memcached.default.svc.cluster.local Address 1: 10.40.2.7 mycache-memcached-1.mycache-memcached.default.svc.cluster.local Address 2: 10.40.0.5 mycache-memcached-0.mycache-memcached.default.svc.cluster.local Address 3: 10.40.1.11 mycache-memcached-2.mycache-memcached.default.svc.cluster.local
Notice that each server has its own domain name of the following form:
[POD_NAME].[SERVICE_NAME].[NAMESPACE].svc.cluster.local
For example, the domain for the mycache-memcached-0 pod is:
mycache-memcached-0.mycache-memcached.default.svc.cluster.local
-
For another alternative, perform the same DNS inspection by using a programming language like Python:
Start a Python interactive console inside your cluster:
$ kubectl run -it --rm python --image=python:3.6-alpine --restart=Never python If you don't see a command prompt, try pressing enter. >>>
-
In the Python console, run these commands:
import socket print(socket.gethostbyname_ex('mycache-memcached.default.svc.cluster.local')) exit()
The output is similar to the following:
If you don't see a command prompt, try pressing enter. >>> import socket >>> print(socket.gethostbyname_ex('mycache-memcached.default.svc.cluster.local')) ('mycache-memcached.default.svc.cluster.local', ['mycache-memcached.default.svc.cluster.local'], ['10.40.2.7', '10.40.1.11', '10.40.0.5']) >>> exit()
Test the deployment by opening a telnet session with one of the running Memcached servers on port 11211:
$ kubectl run -it --rm alpine --image=alpine:3.6 --restart=Never telnet mycache-memcached-0.mycache-memcached.default.svc.cluster.local 11211 If you don't see a command prompt, try pressing enter.
At the telnet prompt, run these commands using the Memcached ASCII protocol:
set mykey 0 0 5 hello get mykey quit
The resulting output is shown here in bold:
set mykey 0 0 5 hello STORED get mykey VALUE mykey 0 5 hello END quit
We are now ready to implement the basic service discovery logic shown in the following diagram.
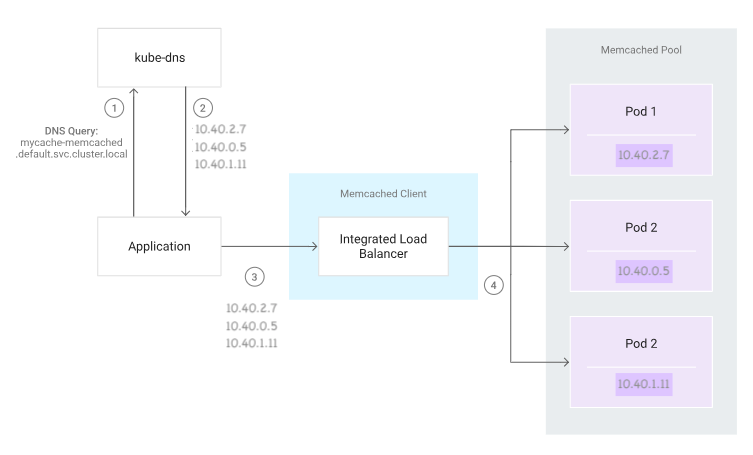
At a high level, the service discovery logic consists of the following steps:
- The application queries kube-dns for the DNS record of mycache-memcached.default.svc.cluster.local.
- The application retrieves the IP addresses associated with that record.
- The application instantiates a new Memcached client and provides it with the retrieved IP addresses.
- The Memcached client's integrated load balancer connects to the Memcached servers at the given IP addresses.
We now implement this service discovery logic by using Python:
-
Deploy a new Python-enabled pod in your cluster and start a shell session inside the pod:
$ kubectl run -it --rm python --image=python:3.6-alpine --restart=Never sh If you don't see a command prompt, try pressing enter. / #
-
Install the pymemcache library:
$ pip install pymemcache ... Successfully installed pymemcache-2.1.1 six-1.12.0
-
Start a Python interactive console by running the python command.
/ # python ... >>>
-
In the Python console, run these commands:
import socket from pymemcache.client.hash import HashClient _, _, ips = socket.gethostbyname_ex('mycache-memcached.default.svc.cluster.local') servers = [(ip, 11211) for ip in ips] client = HashClient(servers, use_pooling=True) client.set('mykey', 'hello') client.get('mykey')
The output is as follows:
b'hello'
The b prefix signifies a bytes literal, which is the format in which Memcached stores data.
-
Exit the Python console:
exit()
- To exit the pod's shell session, press Control+D.
As our caching needs grow, and the pool scales up to dozens, hundreds, or thousands of Memcached servers, we might run into some limitations. In particular, the large number of open connections from Memcached clients might place a heavy load on the servers.
To reduce the number of open connections, we must introduce a proxy to enable connection pooling.
Mcrouter (pronounced "mick router"), a powerful open source Memcached proxy, enables connection pooling. Integrating Mcrouter is seamless, because it uses the standard Memcached ASCII protocol. To a Memcached client, Mcrouter behaves like a normal Memcached server. To a Memcached server, Mcrouter behaves like a normal Memcached client.
To deploy Mcrouter, run the following commands in Cloud Shell.
Delete the previously installed mycache Helm chart release:
$ helm delete mycache --purge release "mycache" deleted
Deploy new Memcached pods and Mcrouter pods by installing a new Mcrouter Helm chart release:
$ helm install stable/mcrouter --name=mycache --set memcached.replicaCount=3 NAME DESIRED CURRENT AGE mycache-memcached 3 1 1s ==> v1beta1/PodDisruptionBudget NAME MIN-AVAILABLE MAX-UNAVAILABLE ALLOWED-DISRUPTIONS AGE mycache-memcached 3 N/A 0 1s ==> v1/ConfigMap NAME DATA AGE mycache-mcrouter 1 1s ==> v1/Service NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE mycache-memcached None
11211/TCP 1s mycache-mcrouter None 5000/TCP 1s NOTES: If you'd like to test your instance, connect to one of the pods and start a telnet session: MCROUTER_POD_IP=$(kubectl get pods --namespace default -l app=mycache-mcrouter -o jsonpath="{.items[0].status.podIP}") kubectl run -it --rm alpine --image=alpine --restart=Never telnet $MCROUTER_POD_IP 5000 In the telnet prompt enter the following commands: set mykey 0 0 5 hello get mykey quit The proxy pods are now ready to accept requests from client applications.
Test this setup by connecting to one of the proxy pods. Use the telnet command on port 5000, which is Mcrouter's default port.
$ MCROUTER_POD_IP=$(kubectl get pods -l app=mycache-mcrouter -o jsonpath="{.items[0].status.podIP}") $ kubectl run -it --rm alpine --image=alpine:3.6 --restart=Never telnet $MCROUTER_POD_IP 5000 If you don't see a command prompt, try pressing enter.
In the telnet prompt, run these commands:
set anotherkey 0 0 15 Mcrouter is fun get anotherkey quit
The commands set and echo the value of our key.
We have now deployed a proxy that enables connection pooling.
To increase resilience, it is common practice to use a cluster with multiple nodes. This tutorial uses a cluster with three nodes. However, using multiple nodes also brings the risk of increased latency caused by heavier network traffic between nodes.
We can reduce this risk by connecting client application pods only to a Memcached proxy pod that is on the same node. The following diagram illustrates the following configuration (Topology for the interactions between application pods, Mcrouter pods, and Memcached pods across a cluster of three nodes).
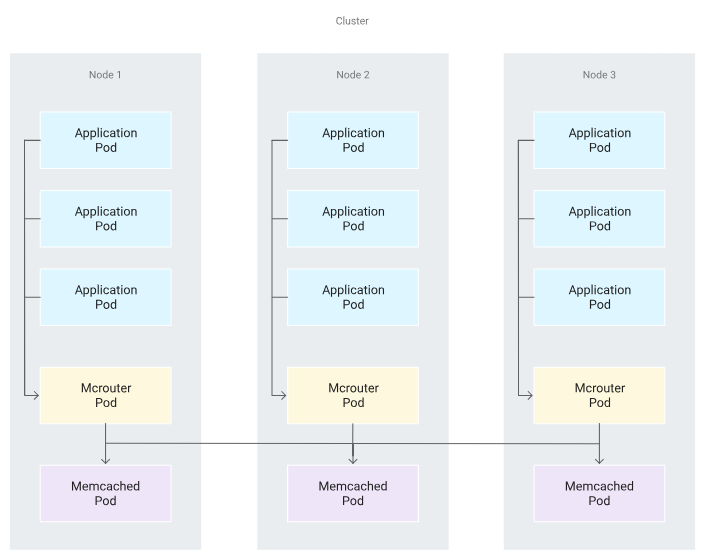
Perform this configuration as follows:
- Ensure that each node contains one running proxy pod. A common approach is to deploy the proxy pods with a DaemonSet controller. As nodes are added to the cluster, new proxy pods are automatically added to them. As nodes are removed from the cluster, those pods are garbage-collected. In this tutorial, the Mcrouter Helm chart that we deployed earlier uses a DaemonSet controller by default. So, this step is already complete.
- Set a hostPort value in the proxy container's Kubernetes parameters to make the node listen to that port and redirect traffic to the proxy. In this tutorial, the Mcrouter Helm chart uses this parameter by default for port 5000. So this step is also already complete.
Expose the node name as an environment variable inside the application pods by using the spec.env entry and selecting the spec.nodeName fieldRef value. See more about this method in the Kubernetes documentation.
Deploy some sample application pods:
$ cat <<EOF | kubectl create -f - apiVersion: extensions/v1beta1 kind: Deployment metadata: name: sample-application spec: replicas: 9 template: metadata: labels: app: sample-application spec: containers: - name: alpine image: alpine:3.6 command: [ "sh", "-c" ] args: - while true; do sleep 10; done; env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName EOF deployment.extensions "sample-application" createdVerify that the node name is exposed, by looking inside one of the sample application pods:
$ POD=$(kubectl get pods -l app=sample-application -o jsonpath="{.items[0].metadata.name}") $ kubectl exec -it $POD -- sh -c 'echo $NODE_NAME' gke-demo-cluster-default-pool-1a7f1d21-v6l2 $ NODE_NAME=gke-demo-cluster-default-pool-1a7f1d21-v6l2
As we can see from the output, this command output the node's name in the following form:
gke-demo-cluster-default-pool-XXXXXXXX-XXXX
The sample application pods are now ready to connect to the Mcrouter pod that runs on their respective mutual nodes at port 5000, which is Mcrouter's default port.
Initiate a connection for one of the pods by opening a telnet session:
$ POD=$(kubectl get pods -l app=sample-application -o jsonpath="{.items[0].metadata.name}") $ kubectl exec -it $POD -- sh -c 'telnet $NODE_NAME 5000'-
In the telnet prompt, run these commands:
get anotherkey quit
Resulting output:
get anotherkey VALUE anotherkey 0 15 Mcrouter is fun END quit Connection closed by foreign host command terminated with exit code 1
Finally, as an illustration, the following Python code is a sample program that performs this connection by retrieving the NODE_NAME variable from the environment and using the pymemcache library:
import os
from pymemcache.client.base import Client
NODE_NAME = os.environ['NODE_NAME']
client = Client((NODE_NAME, 5000))
client.set('some_key', 'some_value')
result = client.get('some_key')
Reference: Deploying Memcached on Google Kubernetes Engine
Docker & K8s
- Docker install on Amazon Linux AMI
- Docker install on EC2 Ubuntu 14.04
- Docker container vs Virtual Machine
- Docker install on Ubuntu 14.04
- Docker Hello World Application
- Nginx image - share/copy files, Dockerfile
- Working with Docker images : brief introduction
- Docker image and container via docker commands (search, pull, run, ps, restart, attach, and rm)
- More on docker run command (docker run -it, docker run --rm, etc.)
- Docker Networks - Bridge Driver Network
- Docker Persistent Storage
- File sharing between host and container (docker run -d -p -v)
- Linking containers and volume for datastore
- Dockerfile - Build Docker images automatically I - FROM, MAINTAINER, and build context
- Dockerfile - Build Docker images automatically II - revisiting FROM, MAINTAINER, build context, and caching
- Dockerfile - Build Docker images automatically III - RUN
- Dockerfile - Build Docker images automatically IV - CMD
- Dockerfile - Build Docker images automatically V - WORKDIR, ENV, ADD, and ENTRYPOINT
- Docker - Apache Tomcat
- Docker - NodeJS
- Docker - NodeJS with hostname
- Docker Compose - NodeJS with MongoDB
- Docker - Prometheus and Grafana with Docker-compose
- Docker - StatsD/Graphite/Grafana
- Docker - Deploying a Java EE JBoss/WildFly Application on AWS Elastic Beanstalk Using Docker Containers
- Docker : NodeJS with GCP Kubernetes Engine
- Docker : Jenkins Multibranch Pipeline with Jenkinsfile and Github
- Docker : Jenkins Master and Slave
- Docker - ELK : ElasticSearch, Logstash, and Kibana
- Docker - ELK 7.6 : Elasticsearch on Centos 7
- Docker - ELK 7.6 : Filebeat on Centos 7
- Docker - ELK 7.6 : Logstash on Centos 7
- Docker - ELK 7.6 : Kibana on Centos 7
- Docker - ELK 7.6 : Elastic Stack with Docker Compose
- Docker - Deploy Elastic Cloud on Kubernetes (ECK) via Elasticsearch operator on minikube
- Docker - Deploy Elastic Stack via Helm on minikube
- Docker Compose - A gentle introduction with WordPress
- Docker Compose - MySQL
- MEAN Stack app on Docker containers : micro services
- MEAN Stack app on Docker containers : micro services via docker-compose
- Docker Compose - Hashicorp's Vault and Consul Part A (install vault, unsealing, static secrets, and policies)
- Docker Compose - Hashicorp's Vault and Consul Part B (EaaS, dynamic secrets, leases, and revocation)
- Docker Compose - Hashicorp's Vault and Consul Part C (Consul)
- Docker Compose with two containers - Flask REST API service container and an Apache server container
- Docker compose : Nginx reverse proxy with multiple containers
- Docker & Kubernetes : Envoy - Getting started
- Docker & Kubernetes : Envoy - Front Proxy
- Docker & Kubernetes : Ambassador - Envoy API Gateway on Kubernetes
- Docker Packer
- Docker Cheat Sheet
- Docker Q & A #1
- Kubernetes Q & A - Part I
- Kubernetes Q & A - Part II
- Docker - Run a React app in a docker
- Docker - Run a React app in a docker II (snapshot app with nginx)
- Docker - NodeJS and MySQL app with React in a docker
- Docker - Step by Step NodeJS and MySQL app with React - I
- Installing LAMP via puppet on Docker
- Docker install via Puppet
- Nginx Docker install via Ansible
- Apache Hadoop CDH 5.8 Install with QuickStarts Docker
- Docker - Deploying Flask app to ECS
- Docker Compose - Deploying WordPress to AWS
- Docker - WordPress Deploy to ECS with Docker-Compose (ECS-CLI EC2 type)
- Docker - WordPress Deploy to ECS with Docker-Compose (ECS-CLI Fargate type)
- Docker - ECS Fargate
- Docker - AWS ECS service discovery with Flask and Redis
- Docker & Kubernetes : minikube
- Docker & Kubernetes 2 : minikube Django with Postgres - persistent volume
- Docker & Kubernetes 3 : minikube Django with Redis and Celery
- Docker & Kubernetes 4 : Django with RDS via AWS Kops
- Docker & Kubernetes : Kops on AWS
- Docker & Kubernetes : Ingress controller on AWS with Kops
- Docker & Kubernetes : HashiCorp's Vault and Consul on minikube
- Docker & Kubernetes : HashiCorp's Vault and Consul - Auto-unseal using Transit Secrets Engine
- Docker & Kubernetes : Persistent Volumes & Persistent Volumes Claims - hostPath and annotations
- Docker & Kubernetes : Persistent Volumes - Dynamic volume provisioning
- Docker & Kubernetes : DaemonSet
- Docker & Kubernetes : Secrets
- Docker & Kubernetes : kubectl command
- Docker & Kubernetes : Assign a Kubernetes Pod to a particular node in a Kubernetes cluster
- Docker & Kubernetes : Configure a Pod to Use a ConfigMap
- AWS : EKS (Elastic Container Service for Kubernetes)
- Docker & Kubernetes : Run a React app in a minikube
- Docker & Kubernetes : Minikube install on AWS EC2
- Docker & Kubernetes : Cassandra with a StatefulSet
- Docker & Kubernetes : Terraform and AWS EKS
- Docker & Kubernetes : Pods and Service definitions
- Docker & Kubernetes : Service IP and the Service Type
- Docker & Kubernetes : Kubernetes DNS with Pods and Services
- Docker & Kubernetes : Headless service and discovering pods
- Docker & Kubernetes : Scaling and Updating application
- Docker & Kubernetes : Horizontal pod autoscaler on minikubes
- Docker & Kubernetes : From a monolithic app to micro services on GCP Kubernetes
- Docker & Kubernetes : Rolling updates
- Docker & Kubernetes : Deployments to GKE (Rolling update, Canary and Blue-green deployments)
- Docker & Kubernetes : Slack Chat Bot with NodeJS on GCP Kubernetes
- Docker & Kubernetes : Continuous Delivery with Jenkins Multibranch Pipeline for Dev, Canary, and Production Environments on GCP Kubernetes
- Docker & Kubernetes : NodePort vs LoadBalancer vs Ingress
- Docker & Kubernetes : MongoDB / MongoExpress on Minikube
- Docker & Kubernetes : Load Testing with Locust on GCP Kubernetes
- Docker & Kubernetes : MongoDB with StatefulSets on GCP Kubernetes Engine
- Docker & Kubernetes : Nginx Ingress Controller on Minikube
- Docker & Kubernetes : Setting up Ingress with NGINX Controller on Minikube (Mac)
- Docker & Kubernetes : Nginx Ingress Controller for Dashboard service on Minikube
- Docker & Kubernetes : Nginx Ingress Controller on GCP Kubernetes
- Docker & Kubernetes : Kubernetes Ingress with AWS ALB Ingress Controller in EKS
- Docker & Kubernetes : Setting up a private cluster on GCP Kubernetes
- Docker & Kubernetes : Kubernetes Namespaces (default, kube-public, kube-system) and switching namespaces (kubens)
- Docker & Kubernetes : StatefulSets on minikube
- Docker & Kubernetes : RBAC
- Docker & Kubernetes Service Account, RBAC, and IAM
- Docker & Kubernetes - Kubernetes Service Account, RBAC, IAM with EKS ALB, Part 1
- Docker & Kubernetes : Helm Chart
- Docker & Kubernetes : My first Helm deploy
- Docker & Kubernetes : Readiness and Liveness Probes
- Docker & Kubernetes : Helm chart repository with Github pages
- Docker & Kubernetes : Deploying WordPress and MariaDB with Ingress to Minikube using Helm Chart
- Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 2 Chart
- Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 3 Chart
- Docker & Kubernetes : Helm Chart for Node/Express and MySQL with Ingress
- Docker & Kubernetes : Deploy Prometheus and Grafana using Helm and Prometheus Operator - Monitoring Kubernetes node resources out of the box
- Docker & Kubernetes : Deploy Prometheus and Grafana using kube-prometheus-stack Helm Chart
- Docker & Kubernetes : Istio (service mesh) sidecar proxy on GCP Kubernetes
- Docker & Kubernetes : Istio on EKS
- Docker & Kubernetes : Istio on Minikube with AWS EC2 for Bookinfo Application
- Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part I)
- Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part II - Prometheus, Grafana, pin a service, split traffic, and inject faults)
- Docker & Kubernetes : Helm Package Manager with MySQL on GCP Kubernetes Engine
- Docker & Kubernetes : Deploying Memcached on Kubernetes Engine
- Docker & Kubernetes : EKS Control Plane (API server) Metrics with Prometheus
- Docker & Kubernetes : Spinnaker on EKS with Halyard
- Docker & Kubernetes : Continuous Delivery Pipelines with Spinnaker and Kubernetes Engine
- Docker & Kubernetes : Multi-node Local Kubernetes cluster : Kubeadm-dind (docker-in-docker)
- Docker & Kubernetes : Multi-node Local Kubernetes cluster : Kubeadm-kind (k8s-in-docker)
- Docker & Kubernetes : nodeSelector, nodeAffinity, taints/tolerations, pod affinity and anti-affinity - Assigning Pods to Nodes
- Docker & Kubernetes : Jenkins-X on EKS
- Docker & Kubernetes : ArgoCD App of Apps with Heml on Kubernetes
- Docker & Kubernetes : ArgoCD on Kubernetes cluster
- Docker & Kubernetes : GitOps with ArgoCD for Continuous Delivery to Kubernetes clusters (minikube) - guestbook
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization